Критерий Фишера в программе STATISTICA в среде Windows
Критерий Фишера
Критерий Фишера применяется при проверке гипотезы о равенстве дисперсий двух генеральных совокупностей, распределенных по нормальному закону. Он является параметрическим критерием.
F-критерий Фишера называют дисперсионным отношением, так как он формируется как отношение двух сравниваемых несмещенных оценок дисперсий.
Пусть в результате наблюдений получены две выборки. По ним вычислены дисперсии 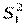 и
и 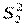 , имеющие
, имеющие 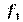 и
и  степеней свободы. Будем считать, что первая выборка взята из генеральной совокупности с дисперсией
степеней свободы. Будем считать, что первая выборка взята из генеральной совокупности с дисперсией  , а вторая – из генеральной совокупности с дисперсией
, а вторая – из генеральной совокупности с дисперсией 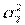 . Выдвигается нулевая гипотеза о равенстве двух дисперсий, т.е. H0:
. Выдвигается нулевая гипотеза о равенстве двух дисперсий, т.е. H0: 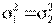 или
или 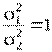 . Для того, чтобы отвергнуть эту гипотезу нужно доказать значимость различия при заданном уровне значимости
. Для того, чтобы отвергнуть эту гипотезу нужно доказать значимость различия при заданном уровне значимости 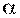 .
.
Значение критерия вычисляется по формуле:
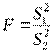 .
.
Очевидно, что при равенстве дисперсий величина критерия будет равна единице. В остальных случаях она будет больше (меньше) единицы.
Критерий имеет распределение Фишера 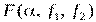 . Критерий Фишера – двусторонний критерий, и нулевая гипотеза
. Критерий Фишера – двусторонний критерий, и нулевая гипотеза 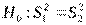 отвергается в пользу альтернативной
отвергается в пользу альтернативной 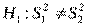 если
если 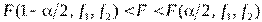 . Здесь
. Здесь 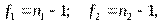 , где
, где 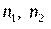 – объем первой и второй выборки соответственно.
– объем первой и второй выборки соответственно.
В системе STATISTICA реализован односторонний критерий Фишера, т.е. в качестве всегда берут максимальную дисперсию. В этом случае нулевая гипотеза отвергается в пользу альтернативы 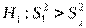 , если
, если 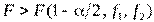 .
.
Пример
Пусть поставлена задача, сравнить эффективность обучения двух групп студентов. Уровень успеваемости - характеризует уровень управления процессом обучения, а дисперсия качество управления обучением, степень организованности процесса обучения. Оба показателя являются независимыми и в общем случае должны рассматриваться совместно. Уровень успеваемости (математическое ожидание) каждой группы студентов характеризуется средними арифметическими 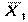 и
и 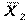 , а качество характеризуется соответствующими выборочными дисперсиями оценок: и . При оценке уровня текущей успеваемости оказалось, что он одинаков у обоих учащихся:
, а качество характеризуется соответствующими выборочными дисперсиями оценок: и . При оценке уровня текущей успеваемости оказалось, что он одинаков у обоих учащихся:  =
= 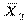 = 4,0. Выборочные дисперсии:
= 4,0. Выборочные дисперсии: 
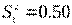 и
и  . Числа степеней свободы, соответствующие этим оценкам:
. Числа степеней свободы, соответствующие этим оценкам: 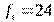 и
и 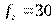 . Отсюда для установления различий в эффективности обучения мы можем воспользоваться стабильностью успеваемости, т.е. проверим гипотезу .
. Отсюда для установления различий в эффективности обучения мы можем воспользоваться стабильностью успеваемости, т.е. проверим гипотезу .
|
|
|
Вычислим 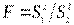 (в числителе должна быть большая дисперсия),
(в числителе должна быть большая дисперсия), 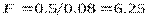 . По таблицам (STATISTICA – Probability Distribution Calculator) находим
. По таблицам (STATISTICA – Probability Distribution Calculator) находим 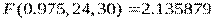 , которое меньше вычисленного, следовательно нулевая гипотеза должна быть отвергнута в пользу альтернативы . Это заключение может не удовлетворить исследователя, поскольку его интересует истинная величина отношения
, которое меньше вычисленного, следовательно нулевая гипотеза должна быть отвергнута в пользу альтернативы . Это заключение может не удовлетворить исследователя, поскольку его интересует истинная величина отношения  (у нас в числителе всегда большая дисперсия). При проверке одностороннего критерия получим
(у нас в числителе всегда большая дисперсия). При проверке одностороннего критерия получим  , что меньше вычисленного выше значения. Итак, нулевая гипотеза должна быть отвергнута в пользу альтернативы .
, что меньше вычисленного выше значения. Итак, нулевая гипотеза должна быть отвергнута в пользу альтернативы .
|
|
|
Критерий Фишера в программе STATISTICA в среде Windows
Для примера проверки гипотезы (критерий Фишера) используем (создаем) файл с двумя переменными (fisher.sta):
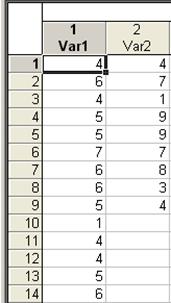
Рис. 1. Таблица с двумя независимыми переменными
Чтобы проверить гипотезу необходимо в базовой статистике (Basic Statistics and Tables) выбрать проверку по Стьюденту для независимых переменных. (t-test, independent, by variables).
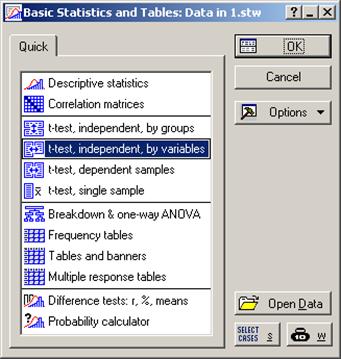
Рис. 2. Проверка параметрических гипотез
После выбора переменных и нажатия на клавишу Summary производится подсчет значений среднеквадратичных отклонений и критерия Фишера. Кроме этого определяется уровень значимости p, при котором различие несущественно.

Рис. 3. Результаты проверки гипотезы (F- критерий)
Используя Probability Calculator и задав значение параметров можно построить график распределения Фишера с пометкой вычисленного значения.
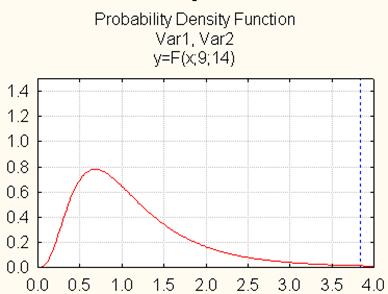
Рис. 4. Область принятия (отклонения) гипотезы (F- критерий)
Источники.
1. Проверка гипотез об отношениях двух дисперсий
URL: /tryphonov3/terms3/testdi.htm
2. Лекция 6. :8080/resources/math/mop/lections/lection_6.htm
3. F – критерий Фишера
|
|
|
URL: /home/portal/applications/Multivariatadvisor/F-Fisheer/F-Fisheer.htm
4. Теория и практика вероятностно-статистических исследований.
URL: /active/referats/read/doc-3663-1.html
5. F – критерий Фишера
URL: /stat/s04.html
Распределœение признака в вариационном ряду по накопленным частотам (частостям) изображается с помощью кумуляты.
Кумулята или кумулятивная кривая в отличие от полигона строится по накопленным частотам или частостям. При этом на оси абсцисс помещают значения признака, а на оси ординат — накопленные частоты или частости (рис. 6.3).
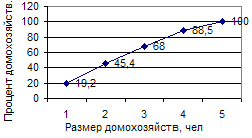
Рис. 6.3. Кумулята распределœения домохозяйств по размеру
4. Рассчитаем накопленные частоты: Наколенная частота первого интервала рассчитывается следующим образом: 0 + 4 = 4, для второго: 4 + 12 = 16; для третьего: 4 + 12 + 8 = 24 и т.д.
| Размер заработной платы руб в месяц Xi | Численность работников чел. fi | Накопленные частоты S |
| до 5000 | ||
| 5000 — 7000 | ||
| 7000 — 10000 | ||
| 10000 — 15000 | ||
| Итого: | - |
При построении кумуляты накопленная частота (частость) соответствующего интервала присваивается его верхней границе:
Огива
Огива строится аналогично кумуляте с той лишь разницей, что накопленные частоты помещают на оси абсцисс, а значения признака — на оси ординат.
|
|
|
Разновидностью кумуляты является кривая концентрации или график Лоренца. Для построения кривой концентрации на обе оси прямоугольной системы координат наносится масштабная шкала в процентах от 0 до 100. При этом на оси абсцисс указывают накопленные частости, а на оси ординат — накопленные значения доли (в процентах) по объёму признака.
Равномерному распределœению признака соответствует на графике диагональ квадрата (рис. 6.4). При неравномерном распределœении график представляет собой вогнутую кривую исходя из уровня концентрации признака.
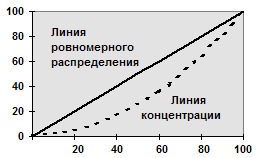
12.Виды абсолютных и относительных показателœей.
Статистический показатель — количественная характеристика социально-экономических явлений и процессов в условиях качественной определœенности.
Различают показатель-категорию и конкретный статистический показатель:
Показатель категория определяет содержание статистического показателя, то есть не численное значение определœенного показателя, а его элементы: к примеру коэффициент рождаемости, смертности, национального богатства.
Конкретный статистический показатель — это цифровая характеристика изучаемого явления или процесса. К примеру: численность населœения России на данный момент составляет 145 млн.человек.
По форме различают статистические показатели:
- Абсолютные
- Относительные
- Средние
По охвату единиц различают индивидуальные и сводные показатели.
Индивидуальные показатели — характеризуют отдельный объект или отдельную единицу совокупности (прибыль фирмы, размер вклада отдельного человека).
Сводные показатели — характеризуют часть совокупности или в всю статистическую совокупность в целом. Их можно получить как объёмные и расчетные. Объемные показатели получают путем сложения значений признака отдельных единиц совокупности. Полученная величина принято называть объёмом признака. Расчетные показатели вычисляются по различным формулам и используются при анализе социально-экономических явлений.
Статистические показатели по временному фактору делятся на:
- Моментные показатели — отражают состояние или уровень явления на определœенный момент времени. К примеру, число вкладов в Сбербанке на конец какого-либо периода.
- Интервальные показатели — характеризуют итоговый результат за период (день, неделя, месяц, квартал, год) в целом. К примеру, объём произведенной продукции за год.
Статистические показатели связаны между собой. По этой причине, чтообы составить целостное представление об изучаемом явлении или процессе, крайне важно рассматривать систему показателœей.
2. Однофакторный дисперсионный анализ для несвязанных выборок
Назначение метода
Метод однофакторного дисперсионного анализа применяется в тех случаях, когда исследуются изменения результативного признака под влиянием изменяющихся условий или градаций какого-либо фактора. В данном варианте метода влиянию каждой из градаций фактора подвергаются разные выборки испытуемых. Градаций фактора должно быть не менее трех. (Градаций может быть и две, но в этом случае мы не сможем установить нелинейных зависимостей и более разумным представляется использование более простых).
Непараметрическим вариантом этого вида анализа является критерий Н Крускала-Уоллиса.
Гипотезы
H0: Различия между градациями фактора (разными условиями) являются не более выраженными, чем случайные различия внутри каждой группы.
H1: Различия между градациями фактора (разными условиями) являются более выраженными, чем случайные различия внутри каждой группы.
2.2. Ограничения метода однофакторного дисперсионного анализа для несвязанных выборок
1. Однофакторный дисперсионный анализ требует не менее трех градаций фактора и не менее двух испытуемых в каждой градации.
2. Результативный признак должен быть нормально распределен в исследуемой выборке.
Правда, обычно не указывается, идет ли речь о распределении признака во всей обследованной выборке или в той ее части, которая составляет дисперсионный комплекс.
3. Пример решения задачи методом однофакторного дисперсионного анализа для несвязанных выборок на примере:
Три различные группы из шести испытуемых получили списки из десяти слов. Первой группе слова предъявлялись с низкой скоростью -1 слово в 5 секунд, второй группе со средней скоростью - 1 слово в 2 секунды, и третьей группе с большой скоростью - 1 слово в секунду. Было предсказано, что показатели воспроизведения будут зависеть от скорости предъявления слов. Результаты представлены в Табл. 1.
Количество воспроизведенных слов Таблица 1
| № испытуемого | Группа 1: низкая скорость | Группа 2: средняя скорость | Группа 3: высокая скорость |
| 1 | 8 | 7 | 4 |
| 2 | 7 | 8 | 5 |
| 3 | 9 | 5 | 3 |
| 4 | 5 | 4 | 6 |
| 5 | 6 | 6 | 2 |
| 6 | 8 | 7 | 4 |
| Суммы | 43 | 37 | 24 |
| Средние | 7,17 | 6,17 | 4,00 |
| Общая сумма | 104 | ||
H0: Различия в объеме воспроизведения слов между группами являются не более выраженными, чем случайные различия внутрикаждой группы.
H1:Различия в объеме воспроизведения слов между группами являются более выраженными, чем случайные различия внутри каждой группы. Используя экспериментальные значения, представленные в Табл. 1, установим некоторые величины, которые будут необходимы для расчета критерия F.
Расчет основных величин для однофакторного дисперсионного анализа представим в таблице:
Таблица 2

Таблица 3
Последовательность операций в однофакторном дисперсионном анализе для несвязанных выборок
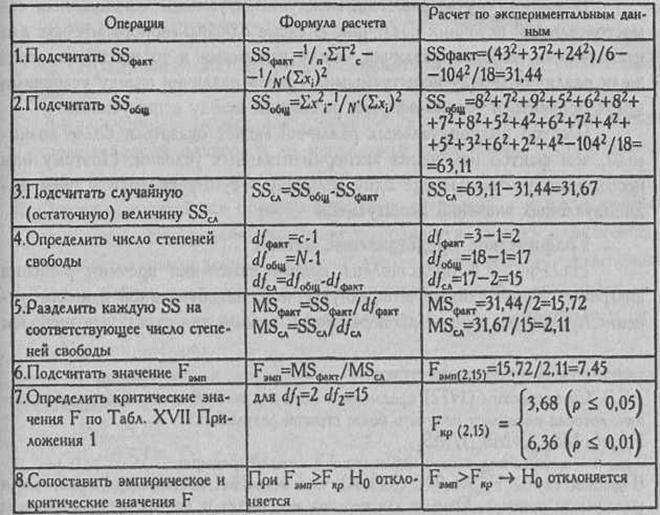
Часто встречающееся в этой и последующих таблицах обозначение SS - сокращение от "суммы квадратов" (sum of squares). Это сокращение чаще всего используется в переводных источниках.
SSфакт означает вариативность признака, обусловленную действием исследуемого фактора;
SSобщ - общую вариативность признака;
SCA -вариативность, обусловленную неучтенными факторами, "случайную" или "остаточную" вариативность.
MS - "средний квадрат", или математическое ожидание суммы квадратов, усредненная величина соответствующих SS.
df - число степеней свободы, которое при рассмотрении непараметрических критериев мы обозначили греческой буквой v.
Вывод: H0 отклоняется. Принимается H1. Различия в объеме воспроизведения слов между группами являются более выраженными, чем случайные различия внутри каждой группы (α=0,05). Итак, скорость предъявления слов влияет на объем их воспроизведения.
Пример решения задачи в Excel представлен ниже:
Исходные данные:
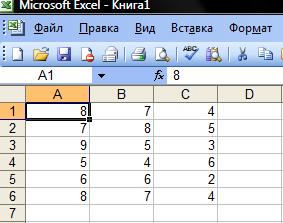
Используя команду: Сервис->Анализ данных->Однофакторный дисперсионный анализ, получим следующие результаты:
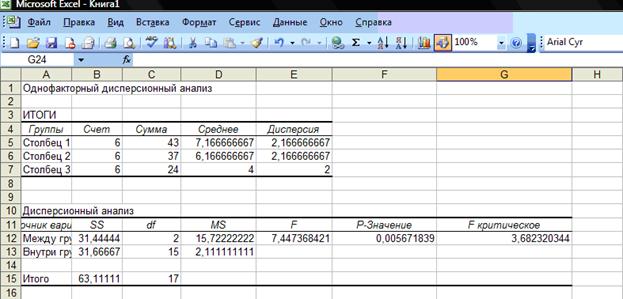
Дата добавления: 2018-06-27; просмотров: 4979; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!