Алгоритм CELP(линейное предсказание с мультикодовым управлением)
Алгоритм CELPоснован на линейной авторегрессионной модели процесса формирования и восприятия речи и входит в группу так называемых методов анализа через синтез (или анализ-синтез), реализующих современные и эффективные алгоритмы информационного сжатия речевых сигналов [9].
Речь может быть представлена моделью авторегрессии (AR) [10]:
 . (16)
. (16)
Каждый отсчёт представлен в виде линейной комбинации предшествующих  отсчётов плюс белый шум. Весовые коэффициенты
отсчётов плюс белый шум. Весовые коэффициенты  являются коэффициентами линейного предсказания (см. п. 2.1.1.). Эти коэффициенты используются в алгоритме CELP для кодирования речевого сигнала [10]. Входной сигнал разбивается на кадры длиной 10-20 мс, в каждом из которых содержится по
являются коэффициентами линейного предсказания (см. п. 2.1.1.). Эти коэффициенты используются в алгоритме CELP для кодирования речевого сигнала [10]. Входной сигнал разбивается на кадры длиной 10-20 мс, в каждом из которых содержится по  отсчётов. Каждый кадр разбивается на меньшие блоки, по
отсчётов. Каждый кадр разбивается на меньшие блоки, по 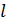 отсчётов в каждом (это значение равно размерности вектора квантования). Такие блоки называют подкадрами. Для каждого кадра находятся свои коэффициенты линейного предсказания. Спектр
отсчётов в каждом (это значение равно размерности вектора квантования). Такие блоки называют подкадрами. Для каждого кадра находятся свои коэффициенты линейного предсказания. Спектр 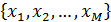 , полученный по вышеописанной модели, приблизительно соответствует спектру кадра входного речевого сигнала.
, полученный по вышеописанной модели, приблизительно соответствует спектру кадра входного речевого сигнала.
Воспользовавшись z-преобразованием для (16), получим:

Из уравнений (16) и (17) можно сделать вывод, что если пропустить белый шум  через фильтр
через фильтр 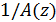 , можно сгенерировать
, можно сгенерировать 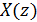 – воспроизведениеречевого сигнала, близкого квходному.
– воспроизведениеречевого сигнала, близкого квходному.
Общая схема CELP кодера показана на рис. 5. Имеется кодовая книга длины  размерности , доступная как кодеру, так и декодеру. Кодовые векторы имеют компоненты, выбранные все независимо из стандартного нормального распределения
размерности , доступная как кодеру, так и декодеру. Кодовые векторы имеют компоненты, выбранные все независимо из стандартного нормального распределения  , поэтому каждый из кодовых векторов приблизительно имеет спектр белого шума. Каждый подкадр входной речи (по отсчётов) обрабатывается следующим образом: каждый кодовый вектор пропускается через 2 фильтра (LPC фильтр и Pitch фильтр
, поэтому каждый из кодовых векторов приблизительно имеет спектр белого шума. Каждый подкадр входной речи (по отсчётов) обрабатывается следующим образом: каждый кодовый вектор пропускается через 2 фильтра (LPC фильтр и Pitch фильтр 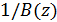 ) и полученный на выходе сигнал
) и полученный на выходе сигнал  сравнивается с отсчётами речи. Кодовый вектор, чей выход наиболее близок к входной речи (наименьшее
сравнивается с отсчётами речи. Кодовый вектор, чей выход наиболее близок к входной речи (наименьшее  – MeanSquaredError), выбирается для представления подкадра.
– MeanSquaredError), выбирается для представления подкадра.
|
|
|
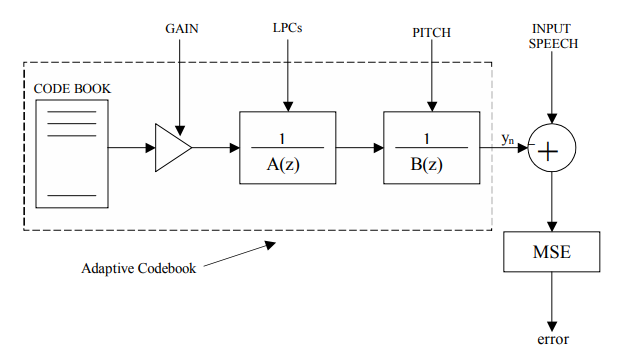
Рис.5. Общая схема CELP, минимизация ошибки посредством выбора лучшего вхождения кодовой книги [10]
Первый фильтр ( ) описывается уравнением (17). Он формирует спектр белого шума кодового вектора, имеющий сходство со спектром входного речевого сигнала. С другой стороны, во временной области фильтр содержит кратковременные корреляции (корреляции с 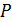 предыдущими отсчётами) в последовательности белого шума. Помимо этого известно, что участки с вокализованной речью проявляют длительную периодичность. Этот период (Pitch, высота тона) включён в синтезированный спектр посредством Pitch фильтра . Поведение временной области этого фильтра может быть выражено следующим образом:
предыдущими отсчётами) в последовательности белого шума. Помимо этого известно, что участки с вокализованной речью проявляют длительную периодичность. Этот период (Pitch, высота тона) включён в синтезированный спектр посредством Pitch фильтра . Поведение временной области этого фильтра может быть выражено следующим образом:
|
|
|
 , (18)
, (18)
где  – входной сигнал,
– входной сигнал,  –сигнал на выходе,
–сигнал на выходе,  –высота тона.
–высота тона.
Речь, синтезированная фильтром, масштабируется соответствующим коэффициентом усиления (gain) для того, чтобы сделать энергию равной энергии входной речи.
Обобщая вышесказанное: на каждом кадре речевого сигнала вычисляются коэффициенты линейного предсказания и высота тона, обновляются фильтры; на каждом подкадре речевого сигнала ( отсчётов) кодовый вектор, который производит «наилучший» фильтрованный выход, выбирается для представления подкадра.
Декодер получает индексы выбранных кодовых векторов и квантованное значение коэффициента усиления для каждого подкадра. Значения коэффициентов линейного предсказания и высоты тона также подлежат квантованию и посылаются на каждом кадре для воссоздания фильтров в декодере. Речевой сигнал воссоздаётся в декодере посредством пропускания выбранных кодовых векторов через фильтры [10].

Рис.6. Основная концепция процесса кодированиявокодераCELP [16]
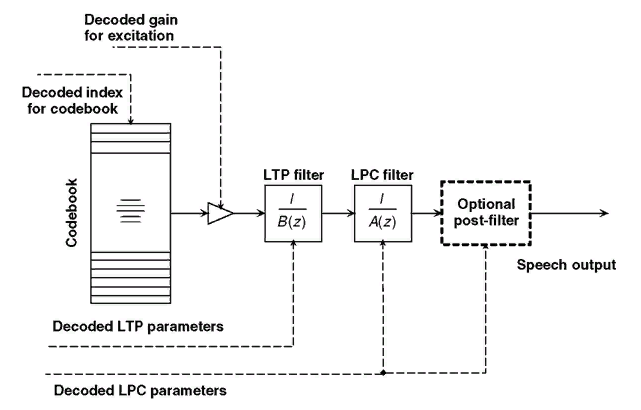
Рис.7. Основная концепция процесса декодирования вокодераCELP [16]
На рис. 6, 7 показана диаграмма, иллюстрирующая концепцию анализ-синтез CELP вокодера. Остановимся более подробно на каждом из компонентов данного вокодера.
|
|
|
Длина каждого кадра берётся равной 20 мс в целях использования для анализа речевого тракта (160 отсчётов с частотой дискретизации 8 кГц), длина блока (подкадра) – 5 мс (40 отсчётов) для определения возбуждения. Декодеру необходимо передать 5 параметров:
· Коэффициенты линейного предсказания a;
· Коэффициент возбуждения G;
· Коэффициент Pitch фильтра;
· Задержку Pitch (высоты тона);
· Индекс кодовой книги.
Алгоритм CELP наиболее эффективно применяется при передаче речевого сигнала в диапазоне скоростей от 4 до 16 Кбит/с.Длина кадра N равна 160 отсчётам, длина подкадраL равна 40 отсчётам. Порядок LP-анализа Mравен 10 (но не всегда). Оценка числа отсчётовв периоде основного тона принимает значения из отрезка [16; 160].
Рассмотрим 2 варианта – 9.6 kbpsCELP вокодер и 16 kbpsCELPвокодер.У первого варианта скорость передачи 9600bps, у второго – 16000 bps.Таблицы кодирования параметров для каждого вокодера приведены ниже [10].
Таблица 4.
Кодирование параметров 9.6 kbpsCELP вокодера в битах.
| Название параметра | Нотация параметра | Число бит на параметр | Число бит на кадр | ||
| Индекс кодовой книги | k | 10 | 40 | ||
| Коэффициенты линейного предсказания |
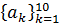
| 6 | 60 | ||
| Коэффициент усиления | G | 7 | 28 | ||
| Коэффициенты Pitch фильтра | b | 8 | 32 | ||
| Запаздывание Pitch фильтра | P | 8 | 32 | ||
| Итого
| 192 | ||||
Таблица 5.
Кодирование параметров 16 kbpsCELP вокодера в битах.
| Название параметра | Нотация параметра | Число бит на параметр | Число бит на кадр |
| Индекс кодовой книги | k | 10 | 40 |
| Коэффициенты линейного предсказания |

| 12 | 144 |
| Коэффициент усиления | G | 13 | 52 |
| Коэффициенты Pitch фильтра | b | 13 | 52 |
| Запаздывание Pitch фильтра | P | 8 | 32 |
| Итого | 320 | ||
Можно заметить, что 16 kbpsCELPвокодер для каждого кадра речевого сигнала использует 12 коэффициентов предсказания  . Кроме того, под каждый параметр выделяется большее количество бит, что обеспечивает лучшее качество синтезированного сигнала по сравнению с 9.6 kbpsCELP вокодером.
. Кроме того, под каждый параметр выделяется большее количество бит, что обеспечивает лучшее качество синтезированного сигнала по сравнению с 9.6 kbpsCELP вокодером.
Дата добавления: 2018-06-27; просмотров: 1237; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!