Построение нелинейной модели (параболическая модель)
Лабораторная работа № 3
Построение регрессионной модели
системы двух случайных величин
Цель работы: изучить основные методы регрессионного и корреляционного анализа; исследовать зависимость между двумя случайными величинами, заданными выборками.
Задание: по виду корреляционного поля сделать предположение о форме регрессионной зависимости между двумя случайными величинами; используя метод наименьших квадратов, найти параметры уравнения регрессии; оценить качество описания зависимости полученным уравнением регрессии.
Пример.По результатам пятнадцати совместных измерений веса грузового поезда, т, и соответствующего времени нахождения поезда на участке Y, ч, представленных в таблице 4.3, следует исследовать зависимость между данными величинами.
Необходимо определить коэффициенты уравнения регрессии методом наименьших квадратов, оценить тесноту связи между величинами, проверить значимость коэффициента корреляции и спрогнозировать время нахождения поезда на участке при заданном весе поезда (5200 т).
Решение. На величину времени нахождения поезда на участке Y, помимо веса X, влияние оказывает качество железнодорожного полотна, качество подвижного состава, топливо и другие факторы. Поэтому зависимость между величиной времени нахождения поезда на участке Y и веса поезда X является статистической: при одном весе поезда при различных дополнительных условиях время нахождения поезда на участке может принимать различные значения.
|
|
|
Для определения вида регрессионной зависимости построим корреляционное поле.
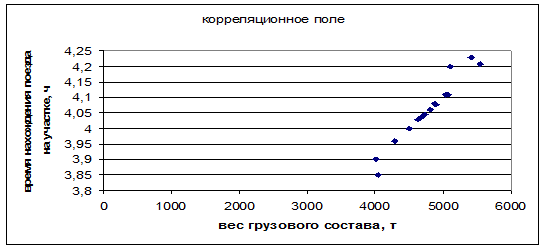
Рисунок 4.1– Корреляционное поле
Построение линейной модели
Характер расположения точек на диаграмме рассеяния позволяет сделать предположение о линейной регрессионной зависимости 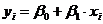 .
.
Таблица 4.1 – Результаты промежуточных вычислений
Вес грузового состава, т, 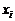
| Время нахождения поезда на участке, час., 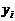
| 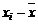
| 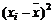
| 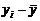
| 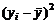
| 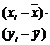
|
| 5100,58 | 4,2 | 327,019 | 106941,2 | 0,14007 | 0,01962 | 45,8044 |
| 4885,41 | 4,078 | 111,849 | 12510,12 | 0,01807 | 0,00033 | 2,02073 |
| 5416,94 | 4,23 | 643,379 | 413936,1 | 0,17007 | 0,02892 | 109,417 |
| 4496,66 | 4,001 | -276,901 | 76674,35 | -0,0589 | 0,00347 | 16,3187 |
| 4722,08 | 4,044 | -51,4813 | 2650,328 | -0,0159 | 0,00025 | 0,82027 |
| 5537,91 | 4,208 | 764,349 | 584228,9 | 0,14807 | 0,02192 | 113,175 |
| 5074,01 | 4,11 | 300,449 | 90269,4 | 0,05007 | 0,00251 | 15,0425 |
| 4807,09 | 4,062 | 33,5287 | 1124,171 | 0,00207 | 0,000043 | 0,06929 |
| 4046,02 | 3,85 | -727,541 | 529316,4 | -0,2099 | 0,04407 | 152,735 |
| 4683,93 | 4,037 | -89,6313 | 8033,776 | -0,0229 | 0,00053 | 2,05555 |
| 4872,42 | 4,08 | 98,8587 | 9773,036 | 0,02007 | 0,0004 | 1,98376 |
| 4003,22 | 3,9 | -770,341 | 593425,8 | -0,1599 | 0,02558 | 123,203 |
| 4628,01 | 4,03 | -145,551 | 21185,19 | -0,0299 | 0,0009 | 4,35684 |
| 4293,44 | 3,96 | -480,121 | 230516,5 | -0,0999 | 0,00999 | 47,9801 |
| 5035,7 | 4,109 | 262,139 | 68716,68 | 0,04907 | 0,00241 | 12,8623 |
| Итого 71603,42 | 60,899 | 0 | 2749302 | 0 | 0,1609 | 647,845 |
|
|
|
Найдем уравнение прямой линии методом наименьших квадратов .
Средний вес грузового состава:
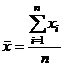 =
= 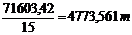 .
.
Среднее значение времени нахождения поезда на участке:
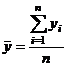 =
= 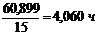
Коэффициенты уравнения:
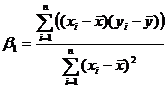
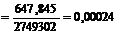
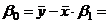
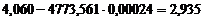
Уравнение регрессии имеет вид :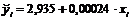 .
.
Для линейной связи коэффициенты:
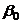 - постоянная регрессии, показывает точку пересечения прямой с осью ординат
- постоянная регрессии, показывает точку пересечения прямой с осью ординат
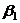 - коэффициент регрессии, показывает меру зависимости переменных y от х, указывает среднюю величину изменения переменной у при изменении х на одну единицу, знак В1 определяет направление этого изменения .
- коэффициент регрессии, показывает меру зависимости переменных y от х, указывает среднюю величину изменения переменной у при изменении х на одну единицу, знак В1 определяет направление этого изменения .
Вычислим линейный коэффициент корреляции
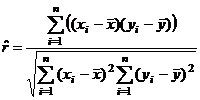 =
= 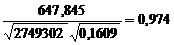 .
.
Таблица 4.2 – Расчет значений времени нахождения поезда на участке по уравнению регрессии
| Вес грузового состава, т,
| Время нахождения поезда на участке, час.,
| 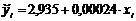
|
| 5100,58 | 4,2 | 4,137 |
| 4885,41 | 4,078 | 4,0863 |
| 5416,94 | 4,23 | 4,2115 |
| 4496,66 | 4,001 | 3,9947 |
| 4722,08 | 4,044 | 4,0478 |
| 5537,91 | 4,208 | 4,24 |
| 5074,01 | 4,11 | 4,1307 |
| 4807,09 | 4,062 | 4,0678 |
| 4046,02 | 3,85 | 3,8885 |
| 4683,93 | 4,037 | 4,0388 |
| 4872,42 | 4,08 | 4,0832 |
| 4003,22 | 3,9 | 3,8784 |
| 4628,01 | 4,03 | 4,0256 |
| 4293,44 | 3,96 | 3,9468 |
| 5035,7 | 4,109 | 4,1217 |
| Итого 71603,42 | 60,899 | 60,899 |
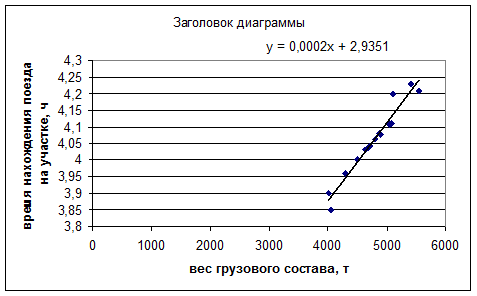
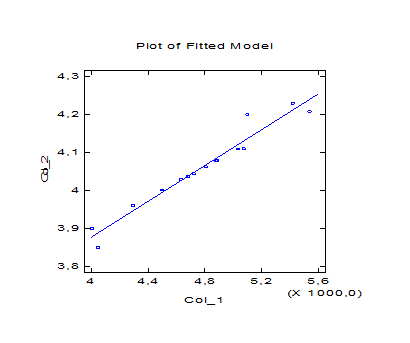
Рисунок 4.2 – Корреляционное поле и линия регрессии
|
|
|
Спрогнозируем время нахождения поезда на участке при заданном весе грузового состава (5200 т).
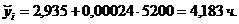
Качественная оценка тесноты связи между величинами выявлена по шкале Чеддока (таблица 4.3).
Таблица 4.3 - Шкала Чеддока
| Теснота связи | Значение коэффициента корреляции при наличии | |
| прямой связи | обратной связи | |
| Слабая | 0,1–0,3 | (-0,1)–(-0,3) |
| Умеренная | 0,3–0,5 | (-0,3)–(-0,5) |
| Заметная | 0,5–0,7 | (-0,5)–(-0,7) |
| Высокая | 0,7–0,9 | (-0,7)–(-0,9) |
| Весьма высокая | 0,9–0,99 | (-0,9)–(-0,99) |
Multiple Regression - Col_2
Dependent variable: Col_2
Independentvariables:
Col_1
| Standard | T | |||
| Parameter | Estimate | Error | Statistic | P-Value |
| CONSTANT | 2,93509 | 0,0727762 | 40,3304 | 0,0000 |
| Col_1 | 0,00023564 | 0,0000151847 | 15,5182 | 0,0000 |
AnalysisofVariance
| Source | SumofSquares | Df | MeanSquare | F-Ratio | P-Value |
| Model | 0,152658 | 1 | 0,152658 | 240,81 | 0,0000 |
| Residual | 0,008241 | 13 | 0,000633923 | ||
| Total (Corr.) | 0,160899 | 14 |
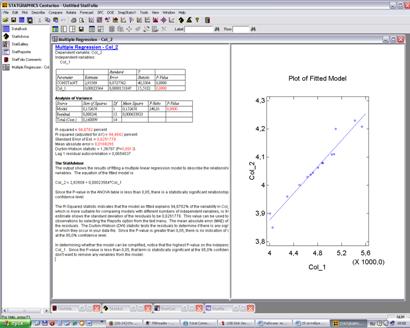
R-squared = 94,8782percent
R-squared (adjusted for d.f.) = 94,4842 percent
Standard Error of Est. = 0,0251778
Mean absolute error = 0,0169255
Durbin-Watson statistic = 1,36787 (P=0,0913)
Lag 1 residual autocorrelation = 0,0654037
The StatAdvisor
The output shows the results of fitting a multiple linear regression model to describe the relationship between Col_2 and 1 independent variables. The equation of the fitted model is
Col_2 = 2,93509 + 0,00023564*Col_1
|
|
|
Since the P-value in the ANOVA table is less than 0,05, there is a statistically significant relationship between the variables at the 95,0% confidence level.
Вывод. Линейный коэффициент корреляции характеризует тесноту связи между двумя коррелируемыми признаками в случае наличия между ними линейной зависимости. Т.к. 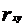 = 0,974, то можно говорить о том, что между величинами X и Y существует линейная прямая, весьма высокая связь.
= 0,974, то можно говорить о том, что между величинами X и Y существует линейная прямая, весьма высокая связь.
Чтобы сделать статистический вывод о значимости коэффициента корреляции (при проверке линейности регрессионной зависимости) выдвигается нулевая гипотеза об отсутствии линейной зависимости между исследуемыми с. в. против альтернативной гипотезы о наличии линейной связи.
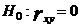 ,
,
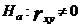 .
.
Если гипотеза H0отклоняется, то считается, что уравнение регрессии Y по X действительно имеет линейный вид .
Для проверки гипотезы H0 вычисляется t-статистика
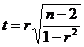 =
= 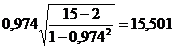 .
.
При условии справедливости гипотезы H0 рассчитанная t-статистика имеет распределение Стьюдента с n – 2 степенями свободы. Найденное значение t = 15,501сравнивается с критическим значением ta,n при n = n – 2 = 15-2 = 13 степенях свободы (приложение А). В нашем случае ta,n = t a=0.05, n=13 = 1,771. Так как расчетное значение 15,501 по абсолютной величине превосходит табличное 1,771 для заданного уровня значимости, то нулевая гипотеза H0 о линейной независимости двух с. в. отклоняется.
Построение нелинейной модели (параболическая модель)
Характер расположения точек на диаграмме рассеяния позволяет сделать предположение о параболической регрессионной зависимости
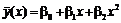 .
.
Оценки параметров b0 , b1 и b2 найдем методом наименьших квадратов. Для этого составим функцию S(b0 , b1 , b2), которая в случае параболической регрессии примет вид
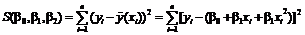 .
.
Для отыскания оценок параметров b0 ,b1 и b2, минимизирующих функцию S(b0 , b1 , b2) , составим и решим систему нормальных уравнений :
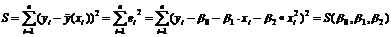
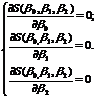 Þ
Þ 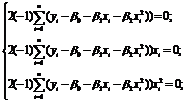 Þ
Þ
Разделим обе части уравнений (1,2,3) на (-2):
Þ 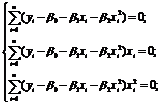 ÞÞ
ÞÞ 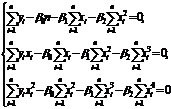 Þ
Þ 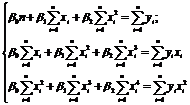
Для вычисления значений сумм, входящих в систему уравнений , составим расчетную таблицу 4.4.
После подстановки значений система уравнений примет вид:
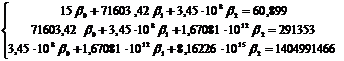
Таблица 4 .4 – Результаты промежуточных вычислений
| Вес грузового состава, т,
| Время нахождения поезда на участке, час.,
| 
| 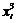
| 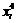
| 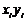
| 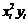
|
| 5100,58 | 4,2 | 26015916 | 1,33 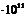
| 6,77 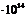
| 21422,44 | 109266848,6 |
| 4885,41 | 4,078 | 23867231 | 1,17
| 5,70
| 19922,70 | 97330567,48 |
| 5416,94 | 4,23 | 29343239 | 1,59
| 8,61
| 22913,66 | 124121900,8 |
| 4496,66 | 4,001 | 20219951 | 0,91
| 4,09
| 17991,14 | 80900024,57 |
| 4722,08 | 4,044 | 22298040 | 1,05
| 4,97
| 19096,09 | 90173271,84 |
| 5537,91 | 4,208 | 30668447 | 1,70
| 9,41
| 23303,53 | 129052825,7 |
| 5074,01 | 4,11 | 25745577 | 1,31
| 6,63
| 20854,18 | 105814323,4 |
| 4807,09 | 4,062 | 23108114 | 1,11
| 5,34
| 19526,4 | 93865160,16 |
| 4046,02 | 3,85 | 16370278 | 0,66
| 2,68
| 15577,18 | 63025569,69 |
| 4683,93 | 4,037 | 21939200 | 1,03
| 4,81
| 18909,03 | 88568551,39 |
| 4872,42 | 4,08 | 23740477 | 1,16
| 5,64
| 19879,47 | 96861144,76 |
| 4003,22 | 3,9 | 16025770 | 0,64
| 2,57
| 15612,56 | 62500504,44 |
| 4628,01 | 4,03 | 21418477 | 0,99
| 4,59
| 18650,88 | 86316460,54 |
| 4293,44 | 3,96 | 18433627 | 079
| 3,40
| 17002,02 | 72997163,05 |
| 5035,7 | 4,109 | 25358274 | 1,28
| 6,43 | 20691,69 | 104197149,9 |
| Итого 71603,42 | 60,899 | 3,45 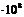
| 1,67 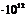
| 8,16 
| 291353,0 | 1404991466,0 |
Решив систему уравнений известными методами (методом Крамера, методом Гаусса, методом обратной матрицы) или с помощью MAthCAD, получим следующее решение: 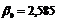 ;
; 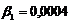 ;
; 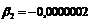 , а уравнение регрессии примет вид
, а уравнение регрессии примет вид
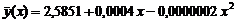 .
.
На рисунке представлена диаграмма рассеяния случайных величин X и Y с нанесённой линией регрессии.
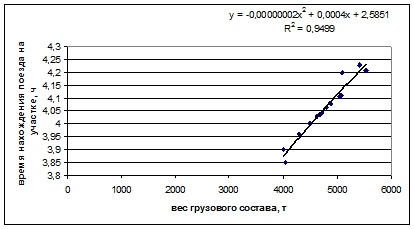
Рисунок 4.4 – Диаграмма рассеяния случайных величин X и Y с нанесённой линией регрессии
Оценим качество описания зависимости между величиной временем нахождения поезда на участке (Y) и весом грузового состава (Х) полученным уравнением регрессии с помощью коэффициента детерминации, где
– значение времени нахождения поезда на участке, предсказываемое уравнением регрессии, при среднем весе грузового состава xi;
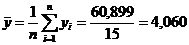 час. – среднеарифметическое наблюденных значений времени нахождения поезда на участке.
час. – среднеарифметическое наблюденных значений времени нахождения поезда на участке.
Таблица 4.6 – Значения времени нахождения поезда на участке
| Вес грузового состава, т,
| Время нахождения поезда на участке, час.,
| Значение, предсказываемое уравнением регрессии 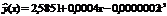
| 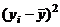
| 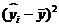
|
| 5100,58 | 4,2 | 4,105 | 0,0196 | 0,00203 |
| 4885,41 | 4,078 | 4,0619 | 0,0003 | 3,9E-06 |
| 5416,94 | 4,23 | 4,165 | 0,0289 | 0,01104 |
| 4496,66 | 4,001 | 3,9794 | 0,0035 | 0,00649 |
| 4722,08 | 4,044 | 4,028 | 0,0003 | 0,00102 |
| 5537,91 | 4,208 | 4,1869 | 0,0219 | 0,01612 |
| 5074,01 | 4,11 | 4,0998 | 0,0025 | 0,00159 |
| 4807,09 | 4,062 | 4,0458 | 4E-06 | 0,0002 |
| 4046,02 | 3,85 | 3,8761 | 0,0441 | 0,03379 |
| 4683,93 | 4,037 | 4,0199 | 0,0005 | 0,0016 |
| 4872,42 | 4,08 | 4,0593 | 0,0004 | 4,6E-07 |
| 4003,22 | 3,9 | 3,8659 | 0,0256 | 0,03766 |
| 4628,01 | 4,03 | 4,0079 | 0,0009 | 0,0027 |
| 4293,44 | 3,96 | 3,9338 | 0,01 | 0,01591 |
| 5035,7 | 4,109 | 4,0922 | 0,0024 | 0,00104 |
| Итого 71603,42 | 60,899 | 60,527 | 0,1609 | 0,152839 |
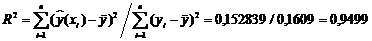
Расчётное значение коэффициента детерминации 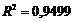 указывает на удовлетворительность описания зависимости между величиной веса грузового состава (Х) и времени нахождения поезда на участке (Y), выбранным уравнением регрессии. Проверим, однако, значимость оценки коэффициента детерминации с помощью статистики Фишера.
указывает на удовлетворительность описания зависимости между величиной веса грузового состава (Х) и времени нахождения поезда на участке (Y), выбранным уравнением регрессии. Проверим, однако, значимость оценки коэффициента детерминации с помощью статистики Фишера.
Проверка значимости 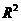 .При выполнении процедуры проверки значимости оценки коэффициента детерминации выдвигается нулевая гипотеза о том, что предложенное уравнение регрессии никак не отражает реальную зависимость между с. в., т. е. H0: R2 = 0. Альтернативная гипотеза заключается в том, что выбранная модель зависимости (уравнение регрессии)
.При выполнении процедуры проверки значимости оценки коэффициента детерминации выдвигается нулевая гипотеза о том, что предложенное уравнение регрессии никак не отражает реальную зависимость между с. в., т. е. H0: R2 = 0. Альтернативная гипотеза заключается в том, что выбранная модель зависимости (уравнение регрессии)  в достаточной степени объясняет действительную зависимость между случайными величинами, т. е. Ha: R2 > 0.
в достаточной степени объясняет действительную зависимость между случайными величинами, т. е. Ha: R2 > 0.
Для проверки значимости оценки коэффициента детерминации используем статистику
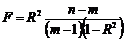 ,
,
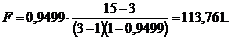
Вывод. Критическое значение статистики Фишера для степеней свободы n1 = 3 – 1 = 2 и n2 = 15 – 3 = 12 и уровня значимости a = 0,05 составляет 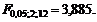 (Приложение Б). Поскольку расчётное значение статистики Фишера больше критического (
(Приложение Б). Поскольку расчётное значение статистики Фишера больше критического ( 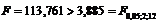 ), то вычисленный коэффициент детерминации значимо отличается от нуля, и выбранное уравнение регрессионной зависимости между величинами скорости и временем нахождения поезда на участке.
), то вычисленный коэффициент детерминации значимо отличается от нуля, и выбранное уравнение регрессионной зависимости между величинами скорости и временем нахождения поезда на участке.
Например, при весе грузового состава 6500 т можно ожидать в среднем время нахождения поезда на участке 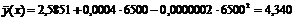 час.
час.
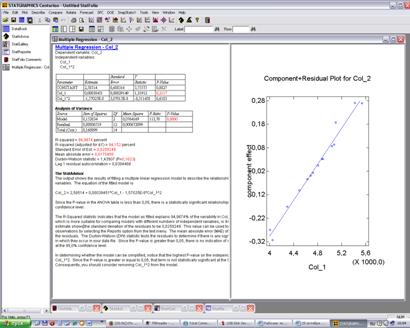
Multiple Regression - Col_2
Dependent variable: Col_2
Independentvariables:
Col_1
Col_1^2
| Standard | T | |||
| Parameter | Estimate | Error | Statistic | P-Value |
| CONSTANT | 2,58514 | 0,688316 | 3,75575 | 0,0027 |
| Col_1 | 0,00038451 | 0,00029149 | 1,31912 | 0,2117 |
| Col_1^2 | -1,57025E-8 | 3,07015E-8 | -0,511458 | 0,6183 |
AnalysisofVariance
| Source | SumofSquares | Df | MeanSquare | F-Ratio | P-Value |
| Model | 0,152834 | 2 | 0,0764169 | 113,70 | 0,0000 |
| Residual | 0,00806519 | 12 | 0,000672099 | ||
| Total (Corr.) | 0,160899 | 14 |
R-squared = 94,9874percent
R-squared (adjusted for d.f.) = 94,152 percent
Standard Error of Est. = 0,0259249
Mean absolute error = 0,0175458
Durbin-Watson statistic = 1,43507 (P=0,1623)
Lag 1 residual autocorrelation = 0,0304468
The StatAdvisor
The output shows the results of fitting a multiple linear regression model to describe the relationship between Col_2 and 2 independent variables. The equation of the fitted model is
Col_2 = 2,58514 + 0,00038451*Col_1 - 1,57025E-8*Col_1^2
Since the P-value in the ANOVA table is less than 0,05, there is a statistically significant relationship between the variables at the 95,0% confidence level.
Порядок выполнения работы
1 Изучить теоретические сведения.
2 Получить у преподавателя выборки значений двух исследуемых случайных величин.
3 Создать в ППП STATGRAPHICS файл с выборками исследуемых случайных величин (см. приложение А, п. 2).
4 По заданной двумерной выборке построить диаграмму рассеяния с помощью ППП STATGRAPHICS (приложение А, п. 10).
5 По виду корреляционного поля сделать предположение о форме регрессионной зависимости между исследуемыми случайными величинами.
6 Найти параметры предполагаемого уравнения регрессии вручную методом наименьших квадратов.
7 Оценить качество описания зависимости между исследуемыми случайными величинами и выбранным уравнением регрессии с помощью коэффициента корреляции (в случае линейной зависимости), или с помощью коэффициента детерминации (в случае нелинейной зависимости).
8 Выполнить регрессионный и корреляционный анализ в ППП STATGRAPHICS с помощью процедуры «Multiple Regression» (см. приложение А, п. 8). Сделать распечатку результатов анализа и уравнения регрессии (приложение А, п. 5).
9 Сравнить результаты ручного расчета и компьютерного анализа.
10 Проверить значимость полученного значения коэффициента корреляции (или детерминации) для ручного и компьютерного расчета.
11 Сформулировать общие выводы о зависимости между исследуемыми случайными величинами.
Контрольные вопросы
1 Какая зависимость называется функциональной? Какая зависимость называется статистической? Привести примеры.
2 Какие случайные величины называются независимыми? Привести примеры.
3 Для чего необходим анализ зависимостей между случайными величинами?
4 Что изучает регрессионный и корреляционный анализ?
5 Какая зависимость называется регрессионной?
6 Для чего применяется метод наименьших квадратов?
7 Сформулируйте идею аппроксимации опытных точек на диаграмме рассеяния методом наименьших квадратов.
8 Что характеризует коэффициент корреляции? На что указывают его возможные значения?
9 Что характеризует коэффициент детерминации? На что указывают его возможные значения?
10 Укажите назначение проверки значимости оценки коэффициента корреляции (детерминации).
Дата добавления: 2018-05-12; просмотров: 1418; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!