Использование стека для постфиксных вычислений
Стеки
Абстрактный стек
Рассмотрим широко известный абстрактный тип данных cтек. Стек является коллекцией в том смысле, что эта структура данных содержит многочисленные элементы. Другие коллекции, с которыми мы встречались, это словари и списки.
Абстрактный тип данных определяется операциями, которые можно выполнять над ним, или, другими словами, интерфейсом. Интерфейс стека включает следующие операции:
__init__
Инициализировать новый пустой стек.
push
Добавить новый элемент к стеку.
pop
Удалить и вернуть элемент из стека. Удаляемый и возвращаемый элемент — всегда последний добавленный в стек элемент.
is_empty
Проверить, пуст ли стек.
Стек иногда называют структурой данных last in, first out (англ.: последним вошел, первым вышел), или LIFO, потому, что последний добавленный в стек элемент всегда извлекается первым.
Реализация стека с помощью списка
Операции над списком, которые предоставляет Python, похожи на операции из интерфейса стека. Напишем код, который реализует операции над стеком с помощью операций над списком.
Этот код будет реализацией абстрактного типа данных стек. Вообще, реализация есть набор методов, которые синтаксически и семантически удовлетворяют требованиям интерфейса.
Вот реализация стека, использующая список Python:
class Stack :
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def is_empty(self):
return (self.items == [])
Класс Stack содержит атрибут items, список Python, содержащий элементы стека. Инициализирующий метод присваивает переменной items пустой список.
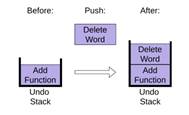
Чтобы поместить новый элемент в стек, push добавляет его в конец списка items.
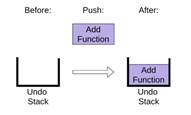
| 
| 
|
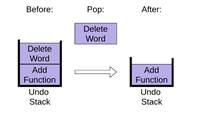
Чтобы извлечь элемент из стека, pop использует одноименный метод списка, удаляющий и возвращающий последний элемент списка.
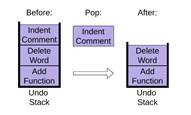
| 
| 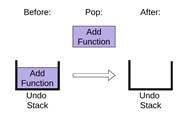
|
И, наконец, чтобы проверить, пуст ли стек, is_empty сравнивает items с пустым списком.
Подобную реализацию, где методы состоят из вызова других существующих методов, иногда называют фасадом. Программисты используют эту метафору, чтобы описать код, скрывающий детали реализации и предоставляющий более простой, или более стандартный, интерфейс.
Помещение в стек и извлечение из стека
Наш стек является обобщенной структурой данных. Это значит, что мы можем поместить в него элемент любого типа. В следующем примере в стек помещаются два целых числа и строка:
>>> s = Stack()
>>> s.push(54)
>>> s.push(45)
>>> s.push("+")
С помощью is_empty и pop мы можем извлечь и вывести на печать все элементы стека:
while not s.is_empty():
print s.pop(),
Получаем + 45 54. Иными словами, мы только что использовали стек, чтобы распечатать элементы в обратном порядке! Хотя это и не стандартный формат вывода списка на печать, однако, с использованием стека вывести список в обратном порядке оказалось очень просто.
Интересно сравнить этот фрагмент кода с реализацией print_backward из предыдущей главы. Существует естественная аналогия между рекурсивной версией print_backward и данным алгоритмом, использующим стек. Разница в том, что print_backward использует стек среды выполнения для размещения узлов списка, и распечатывает их на выходе из рекурсии. Наш стековый алгоритм делает то же самое, только использует объект Stack вместо стека среды выполнения.
Использование стека для постфиксных вычислений
В большинстве языков программирования, математические выражения записываются с операторами между операндов, например, 1 + 2. Такая запись называется инфиксной. Альтернативной формой записи выражений является постфиксная, или обратная польская запись, в которой оператор следует за операндами: 1 2 +.
Постфиксное выражение естественным образом вычисляется с помощью стека:
1. Начав слева, будем брать один терм (оператор или операнд) за один раз.
o Если терм операнд, поместим его в стек.
o Если терм оператор, извлечем два операнда из стека, выполним над ними операцию, и поместим результат в стек.
2. Когда мы доберемся до конца выражения, на стеке останется ровно один операнд. Это и будет результат.
Лексический анализ
Для того, чтобы реализовать описанный алгоритм, необходимо пройти по строке и разбить ее на операнды и операторы. Этот процесс есть ни что иное, как лексический анализ, а его результат – отдельные части строки – называются лексемами. Возможно, вы помните эти понятия из главы 1.
Python предоставляет функции split в модулях string и re (от англ. regular expressions – регулярные выражения). Функция string.split разбивает строку на части, используя указанный символ в качестве разделителя. Например:
>>> import string
>>> string.split("Now is the time", " ")
['Now', 'is', 'the', 'time']
В данном случае разделителем является пробел, и строка разбивается по пробелам.
Более мощная функция re.split позволяет использовать в качестве разделителя регулярное выражение. Регулярное выражение – это способ описания целого множества строк, удовлетворяющих заданному условию. Например, [A-z] есть множество всех букв латинского алфавита, а [0-9] есть множество всех цифр. Оператор ^ “отрицает” множество, так что [^0-9] означает все символы, кроме цифр. Это именно то, что нам нужно для разбиения на лексемы постфиксного выражения:
>>> import re
>>> re.split("([^0-9])", "123 456+8/")
['123', ' ', '456', '+', '8', '/', '']
Обратите внимание, что порядок аргументов re.split отличается от порядка аргументов функции string.split, здесь разделитель идет перед анализируемой строкой.
Результирующий список лексем включает операнды 123, 456, 8, а также операторы + и /. Он также содержит пробел и пустую строку.
Мы посмотрим на следующие реализации стека:
§ list
§ collections.deque
§ queue.LifoQueue
Дата добавления: 2022-12-03; просмотров: 101; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!