Характеристики поизводительности параллельных программ: ускорение, эффективность, формулы для их измерения. Закон Амдала.
Показатели качества параллельного алгоритма
• Ускорение
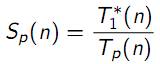 |
• Эффективность
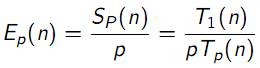 |
Ускорение
• S = p
– Идеальный случай
• S < p
– Последовательные части алгоритма
– Накладные расходы
– Координация
• S > p
– Увеличение кэша и оперативной памяти
– Нелинейная зависимость сложности решения задачи от объема входных данных
– Различные вычислительные схемы
Ускорение vs Эффективность
– Показатели качества параллельного алгоритма часто являются противоречивыми
Максимально достижимое ускорение (Закон Амдала)
– Доля последовательных вычислений
 |
– Время выполнения параллельного алгоритма
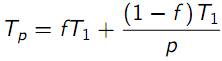 |
– Ускорение
 |
– Максимально достижимое ускорение
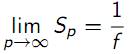 |
S - ускорение работы программы на p процессорах, а f - доля непараллельного кода в программе
Системы с распределенной и общей памятью. Основные средства программирования. Процессы и потоки.
Многие задачи можно распараллелить, тк они содержат независимые компоненты. Растет требуемая производительность, а ресурсы одного процессора ограничены. Поэтому надо вовлекать много процессоров в вычисления.
По типам памяти системы делятся на: системы с общей памятью(много процов, 1 память, например core2duo – у них общая оператива) и системы с распределенной памятью(у каждого проца есть память). На самом деле, хоть чуть чуть своей памяти у процов есть всегда – кеш. Но вообщето под общей памятью тут понимают не маленькую, типа кеша, а именно оперативу – когда из наличия общей памяти следует наличие общей ос.
|
|
|
Процесс – выполнение программы. Процесс имеет собственное адресное пространоство. Контекст процесса – регистры, таблица трансляции адресов памяти, адресное пространство.
Нить(поток) – отличается от процесса тем, что у нее нет своего адресного пространства. (ведь так?)
Задача параллельного программирования – разделить нагрузку между процессорами. Проблемы – балансировка, организация скоростного обмена данными. 2 подхода к решению – (параллелилизм данных) если операция выполняется над большим массивом, разделить массив и отдать куски разным процессорам; (параллелилизм задач) вычисление разбивается на самостоятельные задачи.
Средства:
| \ | Общая память | Распределенная память |
| системные | потоки | Процессы, сокеты |
| языки | C/C++ | HPF, DVM, MPC |
| библиотеки | openMP | MPI, PVM |
Библиотека MPI. Модель SPMD. Точечные и коллективные обмены сообщениями. Библиотека MPI. Коммуникаторы и группы процессов.
В таких системах параллельные процессы обмениваются сообщениями. MPI – это библиотека для такого программирования. MPI – message passing interface. Это библиотека, интерфейсы для разных языков программирования и средства сборки и запуска параллельного приложения.
|
|
|
Приложения, которые пишутся на mpi называются SPMD(single programm, multipy data). Во всех процессах запущена одинаковая программа. Но они обрабатывают различные данные(и поэтому могут выполняться по разным путям).
Коммуникатор – объект, который служит для обозначения некоторой совокупности процессов.
Точечный обмен сообщениями – обмен между 2мя процессами, находящимися в рамках одного коммуникатора.
При пересылке сообщений события могут развиваться по разному, в зависимости от того, в какой последовательности были вызваны функции отправки и приема сообщения. Приемник может начать ждать сообщения ранее или точно в момент отправки сообщения. Тогда все круто. В противном случае (если на момент отправки сообщения его никто не ждет): 1 - ситуация может рассматриваться как ошибочная, 2 - процесс-отправитель блокируется, 3 - сообщение буферизуется. Преимущество 1 – минимальные накладные расходы. Для такого варианта пересылки есть функция MPI_Rsend. Достоинство 2 – отправителю не нужен промежуточный буфер(куда скопировались бы данные из памяти), но недостаток – процесс остановится, а параллельное программирование как раз больше всего экономит время. Второй вариант реализуется функцией MPI_SSend. Третий – MPI_Send. Если памяти хватает, сообщение буферизуется. Если нет, процесс останавливается. Если надо обязательно обеспечить буферизацию, используется MPI_BSend – в ней пользователь сам выделает память.
|
|
|
В качестве номера и тега процесса отправителя может быть или число или одна из предопределенных констант – любой процесс, любой тег
Если на стороне отправителя есть возможность избежать блокировки, то на приемнике, с использованием вышеук. команд – нет. Есть механизм отложенных операций пересылки и приема. Сперва процесс инициализирует прием – ему выдается дескриптор операции приема. Затем он может использовать этот дескриптор чтобы иногда проверять, произошел прием или нет. Когда произошел, по дескриптору он может взять данные. Есть функция MPI_Wait чтобы подождать, когда операция завершится.
Коллективные операции. Самая простая – MPI_Barrier. Аргумент – коммуникатор. Процесс вызывает ее и блокируется, пока все процессы из данного коммуникатора не вызовут ее. Любая коллективная операция должна вызываться всеми процессами, входящими в коммуникатор. MPI_Bcast – функция для рассылки данных всем процессам коммуникатора. Все, даже отправитель должны ее вызвать. Отправитель тоже получит то, что посылал. MPI_Scatter – делит данные поровну между процессами. MPI_Gather – собирает одинаковые блоки данныз, пересылаемые с разных процессов, в массив на одном из них.
|
|
|
Коммуникатор – объект, идентифицирующий некоторое подмножество процессов. Есть предопределенный коммуникатор MPI_COMM_WORLD, в который входят все потоки данного приложения.
Пусть есть коммуникатор, куда входят не все процессы. Всем процессам разослали его копию. Теперь каждый процесс может проверить, входит он в этот коммуникатор или нет. Если он входит, то пусть он выполнит одну какую-то функцию, если не входит, пусть выполнит другую. Вот так при помощи коммуникатора мы заставили процессы делать разные вещи.
Группа процессов - локальный для процесса объект, в котором каждому процессу, входящему в группу, сопоставлено число(отображение идентификаторов процессов на их номера). Количество процессов в группе - функция MPI_Group_size. Процесс может состоять в нескольких группах. Коммуникатор можно создавтаь по группе. Группы можно объединять, пересекать, вычитать.
Каждому коммуникатору соответствует группа входящих в него процессов.
Дата добавления: 2018-02-18; просмотров: 886; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!