Взаимодействие с аппаратной частью
Обзор работы ОС с аппаратной частью
ОС реализуется поверх аппаратной архитектуры, которая определяет способ взаимодействия и набор ограничений. Взаимодействие происходит напрямую — через выдачу инструкций процессору, — и косвенно — через обработку прерываний устройств. С момента начала загрузки ОС указатель на текущую инструкцию процессора (регистр IP) устанавливается в начальную инструкцию исполняемого кода ОС, после чего управление работой процессора переходит к ОС.
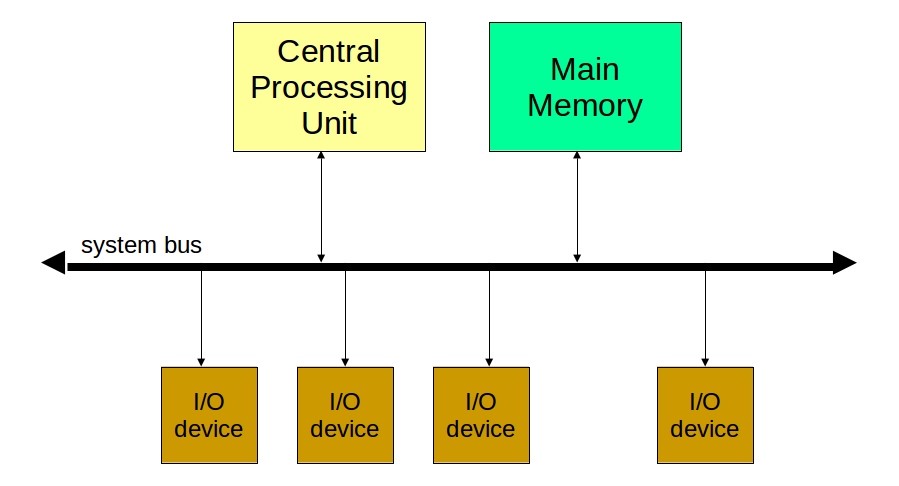
Pис. 3.1. Общий вид аппаратной архитектуры
Взаимодействие процессора с внешними устройствами (также называемое вводом-выводом) возможно только через адресуемую память. Существуют 2 схемы передачи данных между памятью и устройствами: PIO (Programmed IO — ввод-вывод через процессор) и DMA (Direct Memory Access — прямой доступ к памяти). В основном используется второй вариант, который полагается на отдельный контроллер, что позволяет разгрузить процессор от управления вводом-выводом и таким образом ускорить работу системы в целом.
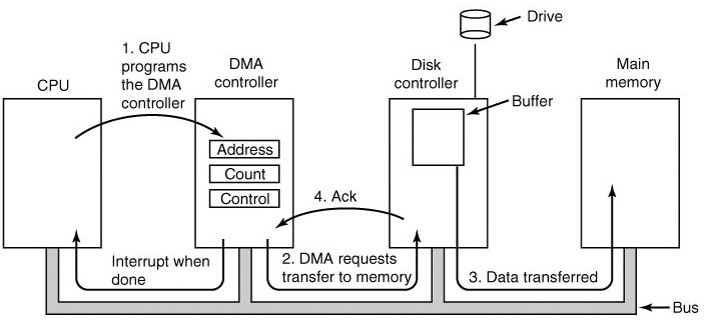
Pис. 3.2. Схема ввода-вывода через DMA
Драйверы устройств
Драйвер устройства — это компьютерная программа, которая реализует механизм управления устройством и позволяет программам более высокого уровня взаимодействовать с конкретным устройством, не зная его команд и других параметров функционирования. Драйвер осуществляет свои функции посредством команд контроллера устройства и обработки прерываний, приходящих от него. Как правило, драйвер реализуется как часть (модуль) ядра ОС, т.к.:
|
|
|
· обработка прерываний драйвером требует задействования функций ОС
· справедливая и эффективная утилизация устройства требует участия ОС
· посылка неверных команд или их последовательностей, а также несоблюдение других условий работы с устройством может вывести его из строя
Драйверы устройств деляться на 3 основных класса:
· Символьные — работают с устройствами, позволяющими передавать данные по 1 символу (байту): как правило, различные консоли, модемы и т.п.
· Блочные — работают с устройствами, позволяющими осуществлять буферизированный ввод-вывод: например, различными дисковыми накопителями
· Сетевые
Pис. 3.3. Классы драйверов
Драйверы отдельных устройств объединяются ОС в классы, которые предоставляют единообразный абстрактный интерфейс программам более высокого уровня. В общем этот интерфейс называется Уровнем абстракции оборудования (Hardware absctraction layer, HAL).
Время на компьютере
Для работы ОС использует аппаратный таймер, который работает на заданной тактовой частоте (на данный момент, как правило 250 Гц). В Linux 1 цикл такого таймера называется jiffies. При этом современные процессоры работают на тактовой частоте порядка 2-3 ГГц, взаимодействие с памятью происходит с частотой порядка десятков МГц, с диском и сетью — порядка сотен КГц. В целом, это создает определенную иерархию операций в компьютере по порядку времени, требуемого для их выполнения. Эффективная работа ядра ОС основывается на знании о том, какие операции допустимы на каком из уровней иерархии.
|
|
|
Прерывания
Аппаратные прерывания
Все операции ввода-вывода требуют продолжительного времени на свое выполнение, поэтому выполняются в асинхронном режиме. Т.е. после выполнения инструкции, вызывающей ввод-вывод, процессор не ждет его завершения, а переключается на выполнение других инструкций. Когда ввод-вывод завершается, устройство сигнализирует об этом посредством прерывания. Такое прерывание называется аппаратным (жестким) или же асинхронным.
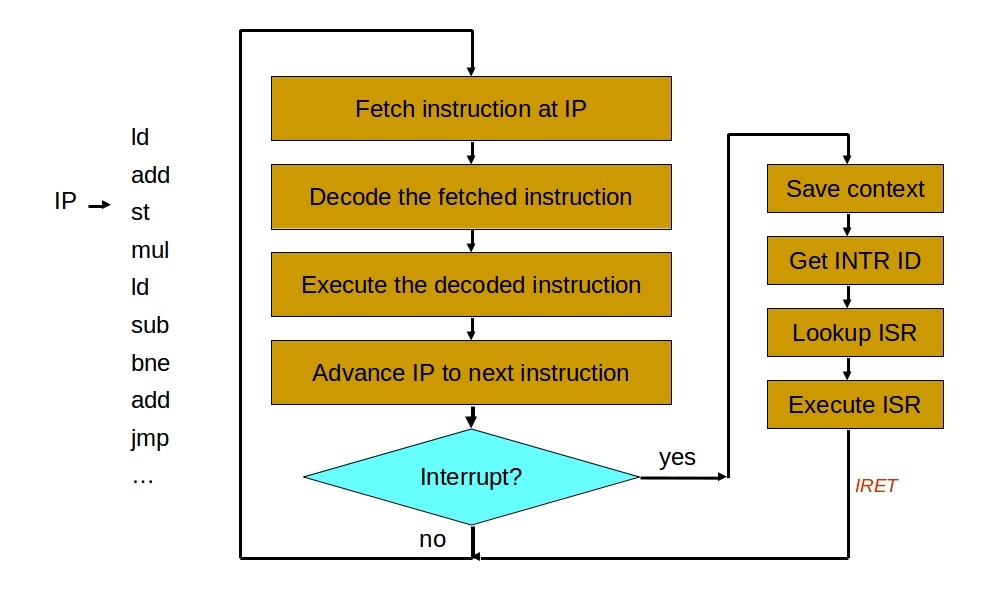
Pис. 3.4. Алгоритм работы процессора
В общем, прерывание — это сигнал, сообщающий процессору о наступлении
какого-либо события. При этом выполнение текущей последовательности команд приостанавливается и управление передаётся обработчику прерывания, который реагирует на событие и обслуживает его, после чего возвращает управление в прерванный код.
|
|
|
PIC (Programmable Interrupt Controller — программируемый контроллер прерываний) — это специальное устройство, которое обеспечивает сигнализацию о прерываниях процессору.
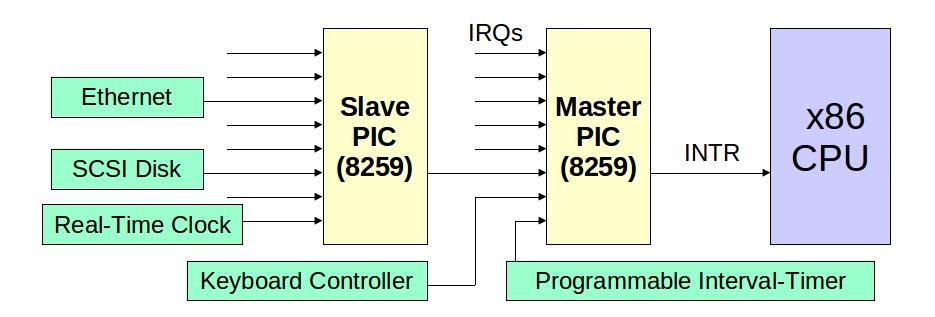
Pис. 3.5. Пример реализации PIC
Программные прерывания
Помимо асинхронных прерываний процессоры поддерживают также синхронные прерывания двух типов:
· Исключения (Exceptions):
o ошибки (fault) — предполагают возможность восстановления,
o ловушки (trap) — сигналы, которые посылаются после выполнения команды и используются для остановки работы процессора (например, при отладке), и
o сбои (abort) — не предполагают восстановления
· Программируемые прерывания
·
В архитектуре х86 предусмотрено 256 синхронных прерываний, из которых первые 32 — это зарезервированные исключения, остальные могут быть произвольно назначены ОС. Примеры стандартных исключений в архитектуре x86 с их номерами:
· 00h Ошибка при выполнении команды деления.
· 01h Прерывание для пошаговой работы, используется отладчиками.
· 02h Немаскируемое прерывание.
· 03h Прерывание по точке останова для отладчиков.
· 04h Переполнение, генерируется командой INTO, если установлен флаг OF.
|
|
|
· 05h генерируется при выполнении машинной команды BOUND, если проверяемое значение вышло за пределы заданного диапазона.
· 06h Недействительный код операции, или длина команды больше 10 байт.
· 07h Отсутствие арифметического сопроцессора.
Схема обработки прерываний
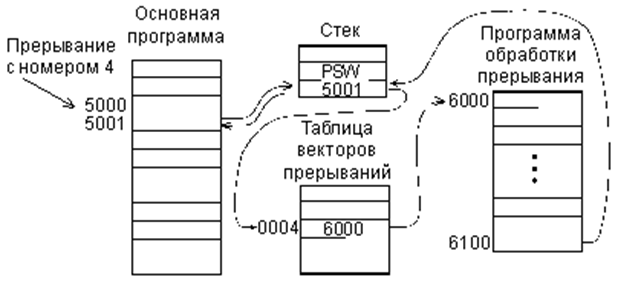
Pис. 3.6. Общая схема системы обработки прерываний
Каждое прерывание имеет уникальный номер, который используется как смещение в таблице обработчиков прерываний. Эта таблица хранится в памяти компьютера и на ее начало указывает специальный регистр процессора - IDT (Interrupt Descriptor Table).
При поступлении сигнала о прерывании его нужно обработать как можно быстрее, для того, чтобы дать возможность производить ввод-вывод другим устройствам. Поэтому процессор сразу переключается в режим обработки прерывания. По номеру прерывания процессор находит процедуру-обработчик в таблице IDT и передает ей управление. Обработчик прерывания, как правило, разбит на 2 части: верхнюю (top half) и нижнюю (bottom half).
Верхняя часть выполняет только тот минимальный набор операций, который необходим, чтобы передать управление дальше. Этот набор включает:
1. подтверждение прерывания (которое разрешает приход новых прерываний)
2. точное определение устройства, от которого пришло прерывание
3. инициализация процедуры обработки нижней части и постановка ее в очередь на исполнение
Процедура нижней части обработчика выполняет копирование данных из буфера устройства в память.
Контексты
Обработчики прерываний работают в т.н. атомарном контексте. Переключение
контекста — это процесс сохранения состояния регистров процессора в память и установки новых значений для регистров. Можно выделить как минимум 3 контекста:
Атомарный, который в свою очередь часто разбит на контекст обработки аппаратных прерываний и программных. В атомарном контексте у процессора нет информации о том, какая программа выполнялась до этого, т.е. нет связи с пользовательской средой. В атомарном контексте нельзя вызывать блокирующие операции, в том числе sleep.
Ядерный (kernel mode) — контекст работы функций самого ядра ОС.
Пользовательский (user mode) — контекст работы функций пользовательской программы, из которого нельзя получить доступ к памяти ядра.
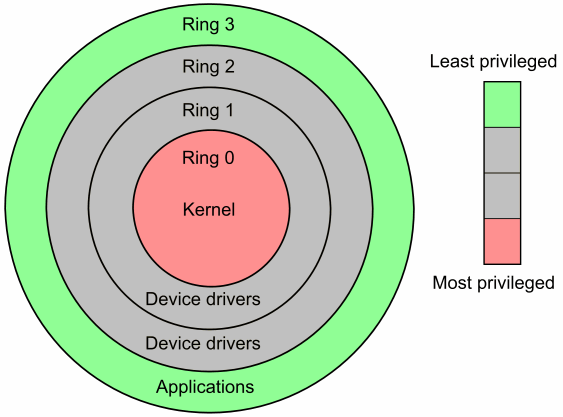
Pис. 3.7. Кольца процессора
Для поддержки разграничения доступа к критическим ресурсам большинство
архитектур реализуют концепцию доменов безопасности или же колец процессора (CPU Rings). Вся память компьютера промаркирована номером кольца безопасности, к которому она относится. Инструкции, находящиеся в памяти, относящейся к тому или иному кольцу, в качестве операндов могут использовать только адреса, которые относятся к кольцам по номеру не более данного. Т.е. программы в кольце 0 имеют максимальные привилегии, а в наибольшем по номеру кольце — минимальные.
На x86 архитектуре колец 4: от 0 до 3. ОС с монолитным или модульным ядром (такие, как Linux) загружаются в кольцо 0, а пользовательские программы — в кольцо 3. Остальные кольца у них не задействованы. В случае микроядерных архитектур некоторые подсистемы ОС могут загружаться в кольца 1 и/или 2.
В соответствии с концепцией доменов безопасности все операции работы с устройствами могут выполняться только из круга 0, т.е. они реализованы в коде ОС и предоставляются пользовательским программам через интерфейс системных вызовов.
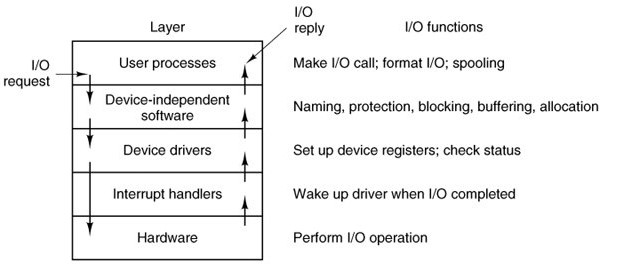
Pис. 3.8. Уровни обработки IO-запроса
Ввод-вывод является продолжительной операцией по шкале процессорного времени. Поэтому оно блокирует вызвавший его процесс для того, чтобы не вызывать простоя процессора.
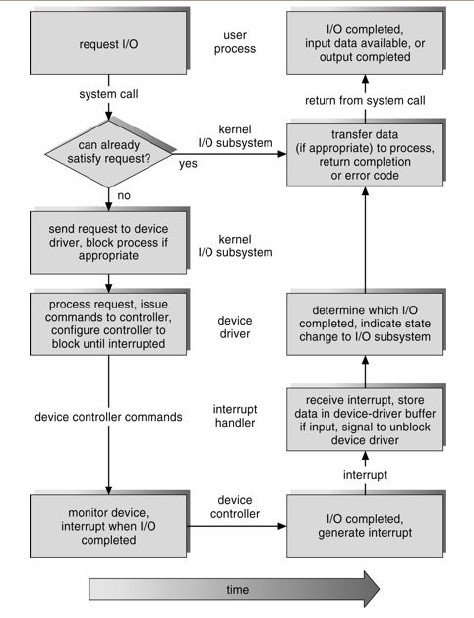
Pис. 3.9. Алгоритм ввода-вывода
Загрузка
Загрузка (bootstrapping) — букв. вытягивание себя за собственные шнурки — процесс многоступенчатой инициализации ОС в памяти компьютера, который проходит через такие этапы:
1. Инициализация прошивки (firmware).
2. Выбор ОС-кандидата на загрузку.
3. Загрузка ядра ОС. На компьютерах с архитектурой x86 этот этап состоит из двух подэтапов:
a. Загрузка в реальном режиме процессора.
b. Загрузка в защищенном режиме.
4. Загрузка компонентов системы в пользовательском окружении.
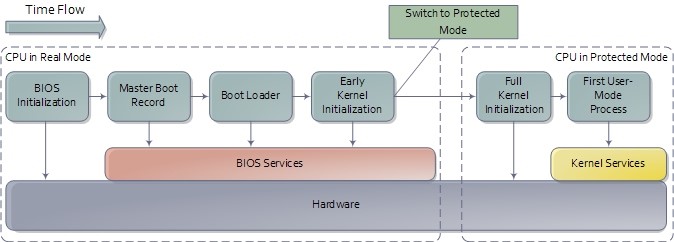
Pис. 3.10. Процесс загрузки ОС на архитектуре x86
Прошивка
Прошивка (Firmware) — это программа, записанная в ROM-память компьютера. На компьютерах общего назначения прошивка выполняет функцию инициализации аппаратной части и передачи управления ОС. Распространенными интерфейсами прошивок являются варианты BIOS, OpenBootProm и UEFI.
BIOS — это стандартный для x86 интерфейс прошивки. Он имеет множество исторических ограничений.
Алгоритм загрузки из BIOS:
1. Power-On Self-Test (POST) — тест работоспособности процессора и памяти после включения питания.
2. Проверка дисков и выбор загрузочного диска.
3. Загрузка Главной загрузочной записи (Master Boot Record, MBR) загрузочного диска в память и передача управления этой программе. MBR может содержать от 1 до 4 записей о разделах диска.
4. Выбор загрузочного раздела. Загрузка загрузочной программы (т.н. 1-й стадии загрузчика) из загрузочной записи выбранного раздела.
5. Выбор ОС для загрузки. Загрузка загрузочной программы самой ОС (т.н. 2-й стадии загрузчика).
6. Загрузка ядра ОС в реальном режиме работы процессора. Большинство современных ОС не могут полностью загрузиться в реальном режиме (из-за жестких ограничений по памяти: для ОС доступно меньше 1МБ памяти). Поэтому загрузчик реального режима загружает в память часть кода ОС и переключает процессор в защищенный режим.
7. Окончательная загрузка ядра ОС в защищенном режиме.
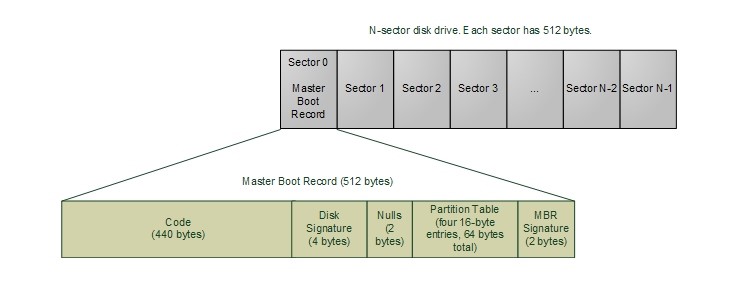
Pис. 3.11. Главная загрузочная запись (MBR)
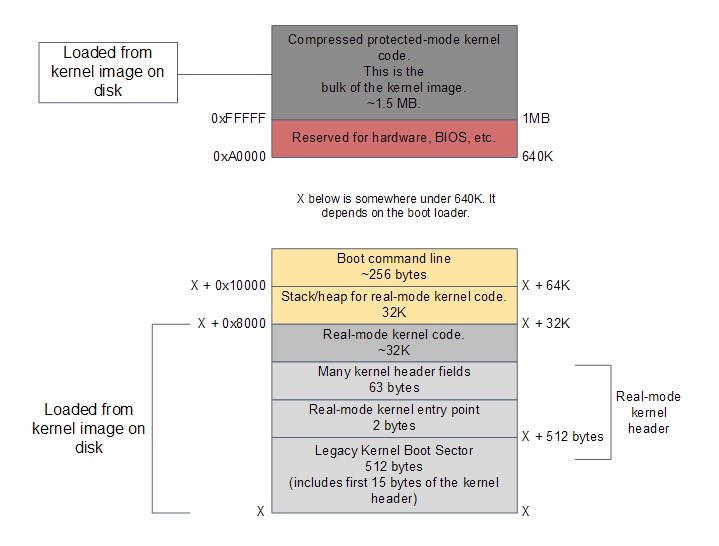
Pис. 3.12. Память компьютера после загрузки ОС
Процесс init
После завершения загрузки ядра ОС, запускается первая программа в пользовательском окружении. В основанных на Unix системах это процесс номер 0, который называется idle. Концептуально этот процесс работает так:

Такой процесс нужен, потому что процессором должны постоянно выполняться какие-то инструкции, он не может просто ждать.
Процессом номер 1 в Unix-системах является процесс init, который запускает все сервисы ОС, которые работают в пользовательском окружении. Это такие сервисы, как графическая оболочка, различные сетевые сервисы, сервис периодического выполнения задач (cron) и др. Конфигурация этих сервисов и последовательности их загрузки выполняется с помощью shell-скриптов, находящихся в директориях /etc/init.d, /etc/rc.d и др.
Бинарный интерфейс
Бинарный интерфейс приложений(ABI)
Бинарный интерфейс приложений — набор формальных спецификаций и неформальных соглашений в рамках программной платформы, обеспечивающих исполнение программ на платформе. Бинарному интерфейсу должны следовать все программы, однако вся работа по его реализации ложится на компилятор и, как правило, прозрачна для прикладных программистов.
Бинарный интерфейс включает:
· спецификацию типов данных: размеры, формат, последовательность байт (endiannes)
· форматы исполняемых файлов
· соглашения о вызовах
· формат и номера системных вызовов ·
и др.
Ассемблер
Ассемблер — это низкоуровневый язык, позволяющий непосредственно кодировать инструкции программной платформы (ОС или виртуальной машины).
Отличия ассемблера от языков более высокого уровня:
· отсутствие единого стандарта, т.е. у каждой архитектуры свой ассемблер
· программа на Ассемблере довольно прямо отражается в бинарный код объектного (исполняемого) файла; обратное преобразование — из объектного файла в ассемблерный код называется дизассемблированием
· в ассемблере нет понятия переменных, а также управляющих конструкций:
· выполнение программы происходит за счет манипуляции данными в регистрах и памяти напрямую, а также вызова других инструкций процессора
· отсутствие каких-либо проверок целостности данных (например, проверки типов)
Синтаксис ассемблера составляют:
· литералы — константные значения, которые представляют сами себя (числа, адреса, строки, регистры)
· команды – мнемоники для записи соответствующих инструкций процессора
· метки — имена для адресов памяти
· директивы компилятора — инструкции компилятору, описывающие различные аспекты создания из программы исполняемого файла (разрядность и секции программы, экспортируемые символы и т.д.) — не записываются напрямую в исполняемую программу
· макросы — конструкции для записи повторяющихся блоков кода, в результате выполнения которых на этапе компиляции выполняется подстановка этих кусков кода вместо имени макроса
Общепринятыми являются 2 синтаксиса ассемблера:
· AT&T
· Intel
Наиболее распространенные ассемблеры для архитектуры x86: SASM, GAS, MASM, TASM. Часть из них являются кроссплатформенными, т.е. работают в разных ОС, а часть — только в какой-либо одной ОС или группе ОС.
Регистры процессора
Команды ассемблера позволяют напрямую манипулировать регистрами процессора. Регистр — это небольшой объем очень быстрой памяти, размещённой на процессоре. Он предназначен для хранения результатов промежуточных вычислений, а также некоторой информации для управления работой процессора. Так как регистры размещены непосредственно на процессоре, доступ к данным, хранящимся в них, намного быстрее доступа к данным в оперативной памяти.
Все регистры можно разделить на две группы: пользовательские и системные. Пользовательские регистры используются при написании "обычных" программ. В их число входят основные программные регистры, а также регистры математического сопроцессора, регистры MMX, XMM (SSE, SSE2, SSE3) и т.п.
К системным регистрам относятся регистры управления, регистры управления памятью, регистры отладки, машинно-специфичные регистры MSR и другие.
Адресация памяти
Ассемблером поддерживаются разные способы адресации памяти:
· непосредственная
· прямая (абсолютная)
· косвенная (базовая)
· автоинкрементная/автодекрементная
· регистровая
· относительная (в случае использования сегментной организации виртуальной памяти)
Порядок байтов (endianness) в машинном слове определяет
последовательность записи байтов: от старшего к младшему (big-endian) или от младшего к старшему (little-endian).
Стек
(Более правильное название используемой структуры данных — стопка или магазин Однако, исторически прижилось заимствованное название стек).
Стек (stack) — это часть динамической памяти, которая используется при вызове функций для хранения ее аргументов и локальных переменных. В архитектуре x86 стек растет вниз, т.е. вершина стека имеет самый маленький адрес. Регистр SP (Stack Pointer) указывает на текущую вершину стека, а регистр BP (Base Pointer) указывает на т.н. базу, которая используется для разделения стека на логические части, относящиеся к одной функции — фреймы (кадры). Помимо обычных инструкций работы с памятью и регистрами (таких как mov), дополнительно для манипуляции стеком используются инструкции push и pop, которые заносят данные на вершину стека и забирают данные с вершины. Эти инструкции также осуществляют изменение регистра SP.
Как правило, в программах на высокоуровневых языках программирования нет кода для работы со стеком напрямую, а это делает за кадром компилятор, реализуя определенные соглашения о вызовах функций и способы хранения локальных переменных. Однако функция alloca библиотеки stdlib позволяет программно выделять память на стеке.
Вызов функции высокоуровневого языка создает на стеке новый фрейм, который содержит аргументы функции, адрес возврата из функции, указатель на начало предыдущего фрейма, а также место под локальные переменные.
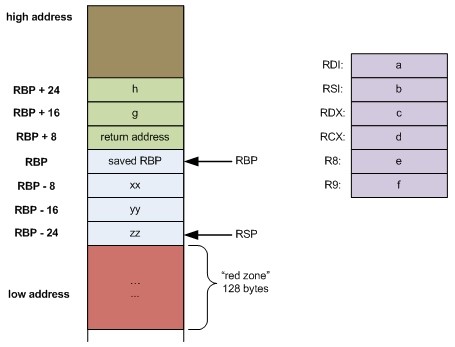
Pис. 4.1. Вид фрейма стека при вызове в рамках AMD64 ABI
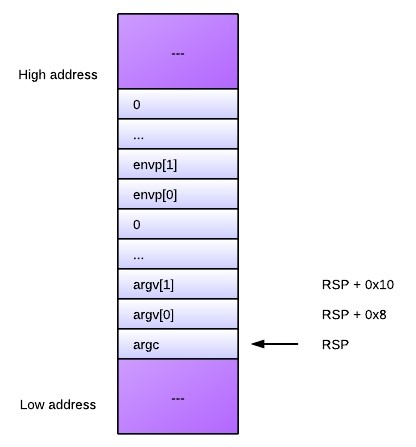 В начале работы программы в стеке выделен только 1 фрейм для функции main и ее аргументов — числового значения argc и массива указателей переменной длины argv, каждый из которых записывается на стек по отдельности, а также переменных окружения.
В начале работы программы в стеке выделен только 1 фрейм для функции main и ее аргументов — числового значения argc и массива указателей переменной длины argv, каждый из которых записывается на стек по отдельности, а также переменных окружения.
Pис. 4.2. Вид стека после вызова функции main
Соглашение о вызовах
Соглашение о вызовах — это схема, в соответствии с которой вызов функции высокоуровневого языка программирования реализуется в исполняемом коде. Соглашение о вызовах отвечает на вопросы:
· Как передаются аргументы и возвращаются значения? Они могут передаваться либо в регистрах, либо через стек, либо и так, и так (гибридная схема).
· Как распределяется работа (по манипуляции стеком вызовов) между вызывающей и вызванной стороной?
В принципе, соглашения не являются жестким стандартом, и программа не обязана следовать тому или иному соглашению для собственных функций (поэтому программы на ассемблере не всегда следуют ему), однако компиляторы создают исполняемые файлы в соответствии с тем или иным соглашением. Кроме того, соглашения о вызовах для библиотечных функций может отличаться от соглашения для системных вызовов: например, аргументы системных вызовов могут передаваться через регистры, а библиотечных функций — через стек.
Распространенные соглашения:
cdecl — общепринятое соглашение для программ на языке С в архитектуре IA32: параметры кладутся на стек справа-налево, вызывающая функция отвечает за очистку стека после возврата из вызванной функции
stdcall (winAPI) — стандартное соглашения для Win32/64: параметры кладутся на стек справа-налево, функция может использовать регистры EAX (RAX), ECX (RCX) и EDX (RDX), вызванная функция отвечает за очистку стека перед возвратом
fastcall — нестандартные соглашения, в которых передача одного или более параметров происходит через регистры для ускорения вызова
pascal— параметры кладутся на стек слева-направо (противоположно cdecl) и вызванная функция отвечает за очистку стека перед возвратом
·thiscall — соглашение для С++
safecall— соглашение для COM/OLE
syscall
optlink
AMD64 ABI
Microsoft x86 calling convention
Пример вызова в соответствии с соглашением cdecl:
Код на языке С:


Сгенерированный компилятором ассемблерный код:

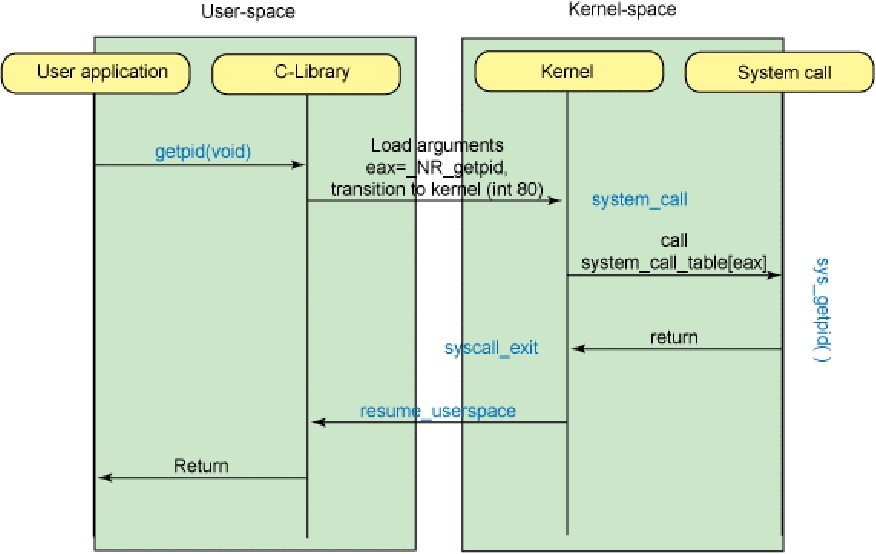
Системные вызовы
В общем, системный вызов — это произвольная функция, которая реализуется ядром ОС и доступна для вызова из пользовательской программы. При выполнении системного вызова происходит переключение контекста из пользовательского в ядерный. Поэтому на уровне команд процессора системный вызов выполняется не как обычный вызов функции (инструкция), а с помощью программного прерывания (в Linux это прерывание номер 80) или же с помощью инструкции SYSENTER (более современный вариант).
Пример выполнения системного вызова write с помощью программного прерывания:

Пример выполнения системного вызова write с помощью инструкции
 :
:
Pис. 4.3. Схема выполнения системного вызова
Управление памятью
Аппаратное управление памятью
Большинство компьютеров используют большое количество различных запоминающих устройств, таких как: ПЗУ, ОЗУ, жесткие диски, магнитные носители и т.д. Все они представляют собой виды памяти, которые доступны через разные интерфейсы. Два основных интерфейса — это прямая адресация процессором и файловые системы. Прямая адресация подразумевает, что адрес ячейки с данными может быть аргументом инструкций процессора.
Режимы работы процессора x86:
· реальный — прямой доступ к памяти по физическому адресу
· защищенный — использование виртуальной памяти и колец процессора для разграничения доступа к ней
Виртуальная память
Виртуальная память — это подход к управлению памятью компьютером, который скрывает физическую память (в различных формах, таких как: оперативная память, ПЗУ или жесткие диски) за единым интерфейсом, позволяя создавать программы, которые работают с ними как с единым непрерывным массивом памяти с произвольным доступом.
Решаемые задачи:
· поддержка изоляции процессов и защиты памяти путём создания своего собственного виртуального адресного пространства для каждого процесса
· поддержка изоляции области ядра от кода пользовательского режима
· поддержка памяти только для чтения и с запретом на исполнение
· поддержка выгрузки не используемых участков памяти в область подкачки на диске (свопинг)
· поддержка отображённых в память файлов, в том числе загрузочных модулей
· поддержка разделяемой между процессами памяти, в том числе с копированием-при-записи для экономии физических страниц
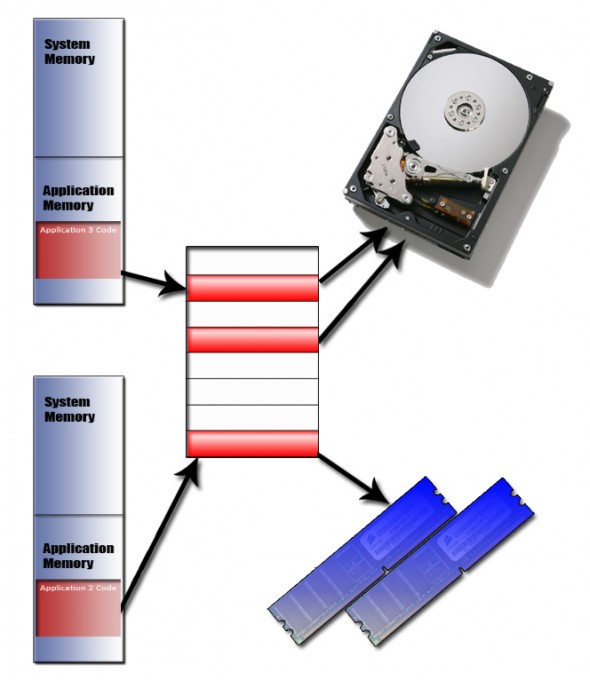
Pис. 5.1. Абстрактное представление виртуальной памяти
Виды адресов памяти:
· физический - адрес аппаратной ячейки памяти
· логический - виртуальный адрес, которым оперирует приложение
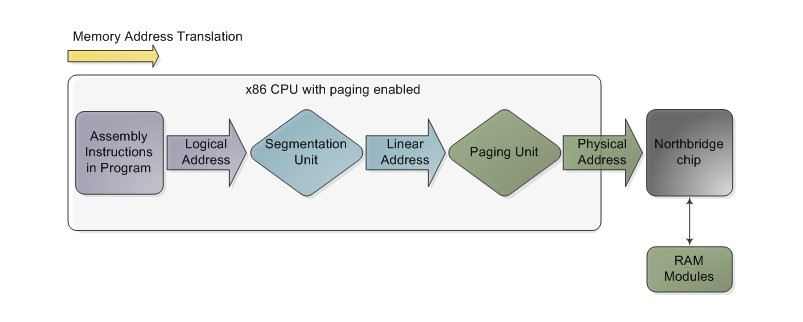
Pис. 5.2. Трансляция логического адреса в физический
За счет наличия механизма виртуальной памяти компиляторы прикладных программ могут генерировать исполняемый код в рамках упрощенной абстрактной линейной модели памяти, в которой вся доступная память представляется в виде непрерывного массива машинных слов, адресуемого с 0 до максимально возможного адреса для данной разрядности (2n, где n количество бит, т.е. для 32-разрядной архитектуры максимальный адрес — 232 = 0xFFFFFFFF). Это значит, что результирующие программы не привязаны к конкретным параметрам запоминающих устройств, таких как их объем, режим адресации и т.д.
Кроме того, этот дополнительный уровень позволяет через тот же самый интерфейс обращения к данным по адресу в памяти реализовать другие функции, такие как обращение к данным в файле (через механизм nmap) и т.д.
На аппаратном уровне виртуальная память, как правило, поддерживается специальным устройством — Модулем управления памятью.
Страничная организация памяти
Страничная память — способ организации виртуальной памяти, при котором единицей отображения виртуальных адресов на физические является регион постоянного размера — страница.
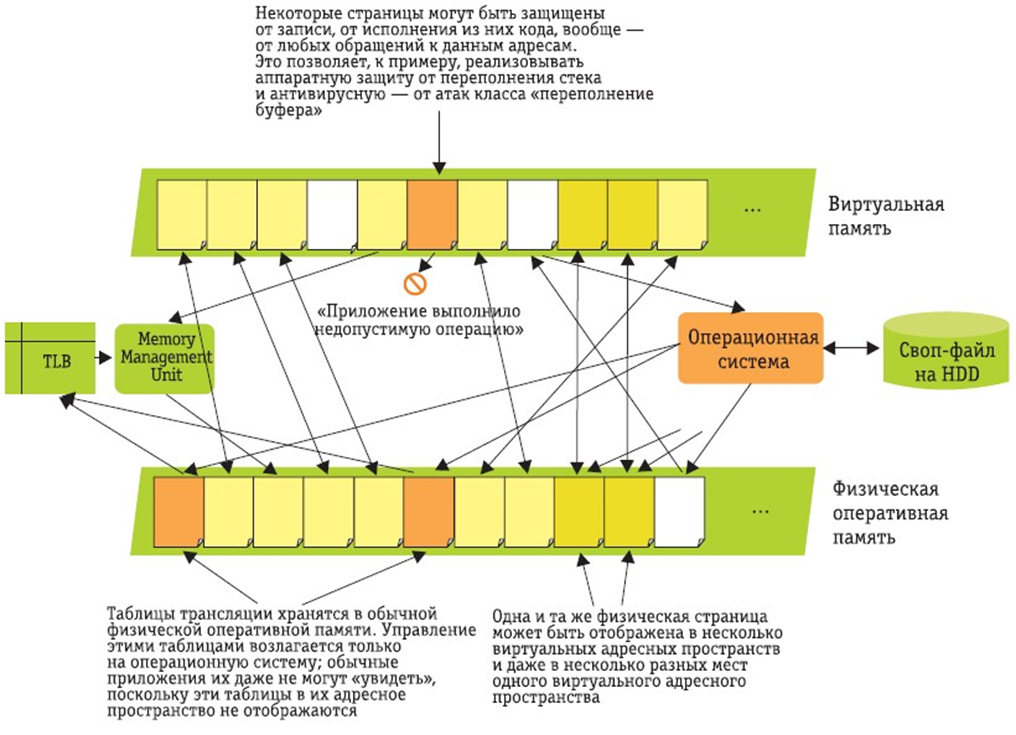
Pис. 5.3. Трансляция адреса в страничной модели
При использовании страничной модели вся виртуальная память делится на N страниц таким образом, что часть виртуального адреса интерпретируется как номер страницы, а часть — как смещение внутри страницы. Вся физическая память также разделяется на блоки такого же размера — фреймы. Таким образом в один фрейм может быть загружена одна страница. Свопинг — это выгрузка страницы из памяти на диск (или другой носитель большего объема), который используется тогда, когда все фреймы заняты. При этом под свопинг попадают страницы памяти неактивных на данный момент процессов.
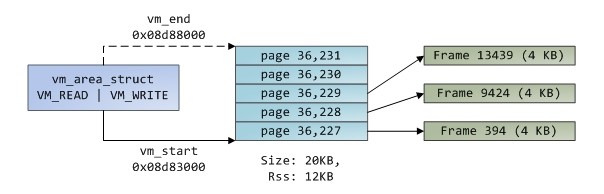
Pис. 5.4. Память процесса в страничной модели
Таблица соответствия фреймов и страниц называется таблицей страниц. Она одна для всей системы. Запись в таблице страниц включает служебную информацию, такую как: индикаторы доступа только на чтение или на чтение/запись, находится ли страница в памяти, производилась ли в нее запись и т.д. Страница может находится в трех состояниях: загружена в память, выгружена в своп, еще не загружена в память (при изначальном выделении страницы она не всегда сразу размещается в памяти).

Pис. 5.5. Запись в таблице страниц
Размер страницы и количество страниц зависит от того, какая часть адреса выделяется на номер страницы, а какая на смещение. К примеру, если в 32-разрядной системе разбить адрес на две равные половины, то количество страниц будет составлять 216, т.е. 65536, и размер страницы в байтах будет таким же, т.е. 64 КБ. Если уменьшить количество страниц до 212, то в системе будет 4096 страницы по 1МБ, а если увеличить до 220, то 1 миллион страниц по 4КБ. Чем больше в системе страниц, тем больше занимает в памяти таблица страниц, соответственно работа процессора с ней замедляется. А поскольку каждое обращение к памяти требует обращения к таблице страниц для трансляции виртуального адреса, такое замедление очень нежелательно. С другой стороны, чем меньше страниц и, соответственно, чем они больше по объему — тем больше потери памяти, вызванные внутренней фрагментацией страниц, поскольку страница является единицей выделения памяти. В этом заключается дилемма оптимизации страничной памяти. Она особенно актуальна при переходе к 64-разрядным архитектурам.
Для оптимизации страничной памяти используются следующие подходы:
· специальный кеш — TLB (translation lookaside buffer) — в котором хранится очень небольшое число (порядка 64) наиболее часто используемых адресов страниц (основные страницы, к которым постоянно обращается ОС)
· многоуровневая (2, 3 уровня) таблица страниц — в этом случае виртуальный адрес разбивается не на 2, а на 3 (4,...) части. Последняя часть остается смещением внутри страницы, а каждая из остальных задает номер страницы в таблице страниц 1-го, 2-го и т.д. уровней. В этой схеме для трансляции адресов нужно выполнить не 1 обращение к таблице страниц, а 2 и более. С другой стороны, это позволяет свопить таблицы страниц 2-го и т.д. уровней, и подгружать в память только те таблицы, которые нужны текущему процессу в текущий момент времени или же даже кешировать их. А каждая из таблиц отдельного уровня имеет существенно меньший размер, чем имела бы одна таблица, если бы уровень был один
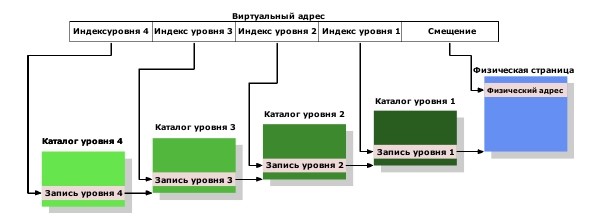
Pис. 5.6. Многоуровневная система страниц
· ·инвертированная таблица страниц — в ней столько записей, сколько в системе фреймов, а не страниц, и индексом является номер фрейма: а число фреймов в 64- и более разрядных архитектурах существенно меньше теоретически возможного числа страниц. Проблема такого подхода — долгий поиск виртуального адреса. Она решается с помощью таких механизмов как: хеш-таблицы или кластерные таблицы страниц
Сегментная организация памяти
Сегментная организация виртуальной памяти реализует следующий механизм: вся память делиться на сегменты фиксированной или произвольной длины, каждый из которых характеризуется своим начальным адресом — базой или селектором. Виртуальный адрес в такой системе состоит из 2-х компонент:
базы сегмента, к которому мы хотим обратиться, и смещения внутри сегмента. Физический адрес вычисляется по формуле:
addr=base+offset
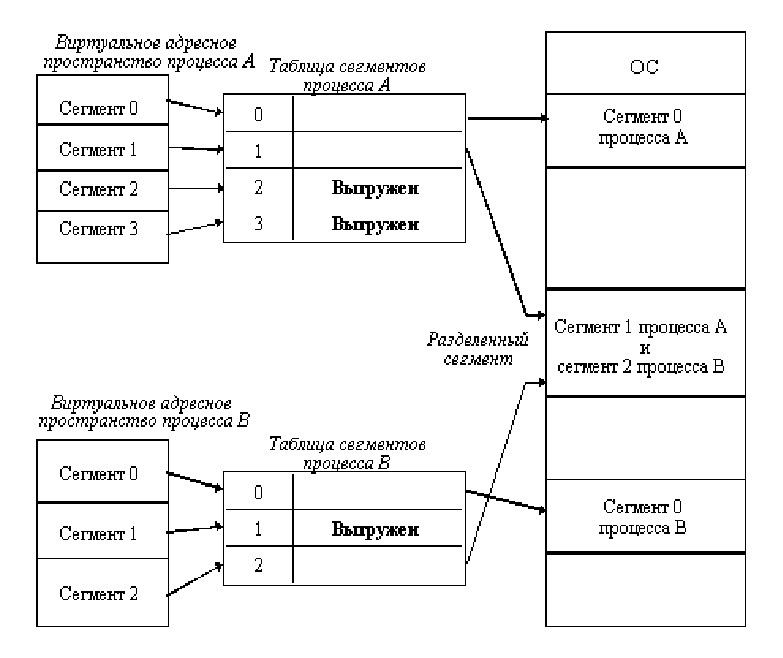
Pис. 5.7. Представление сегментной модели виртуальной памяти
В архитектуре х86 сегментная модель памяти была впервые реализована на 16-разрядных процессорах 8086. Используя только 16 разрядов для адреса давало возможность адресовать только 216 байт, т.е. 64КБ памяти. В то же время стандартный размер физической памяти для этих процессоров был 1МБ. Для того, чтобы иметь возможность работать со всем доступным объемом памяти и была использована сегментная модель. В ней у процессора было выделено 4 специализированных регистра CS (сегмент кода), CC (сегмент стека), DS (сегмент данных), ES (расширенный сегмент) для хранения базы текущего сегмента (для кода, стека и данных программы).
Физический адрес в такой системе рассчитывался по формуле:
addr=base <<4 + offset
Это приводило к возможности адресовать большие адреса, чем 1МБ — т.н. Gate A20.
Плоская модель сегментации
32-разрядный процессор 80386 мог адресовать 232 байт памяти, т.е. 4ГБ, что более чем перекрывало доступные на тот момент размеры физической памяти, поэтому изначальная причина для использования сегментной организации памяти отпала.
Однако, помимо особого способа адресации сегментная модель также предоставляет механизм защиты памяти через кольца безопасности процессора: для каждого сегмента в таблице сегментов задается значение допустимого уровня привилегий (DPL), а при обращении к сегменту передается уровень привилегий текущей программы (запрошенный уровень привилегий, RPL) и, если RPL > DPL доступ к памяти запрещен. Таким образом обеспечивается защита сегментов памяти ядра ОС, которые имеют DPL = 0. Также в таблице сегментов задаются другие атрибуты сегментов, такие как возможность записи в память, возможность исполнения кода из нее и т.д.
Таблица сегментов каждого процесса находится в памяти, а ее начальный адрес загружается в регистр LDTR процессора. В регистре GDTR процессора хранится указатель на глобальную таблицу сегментов.
В современных процессорах x86 используется «Плоская модель сегментации», в которой база всех сегментов выставлена в нулевой адрес.
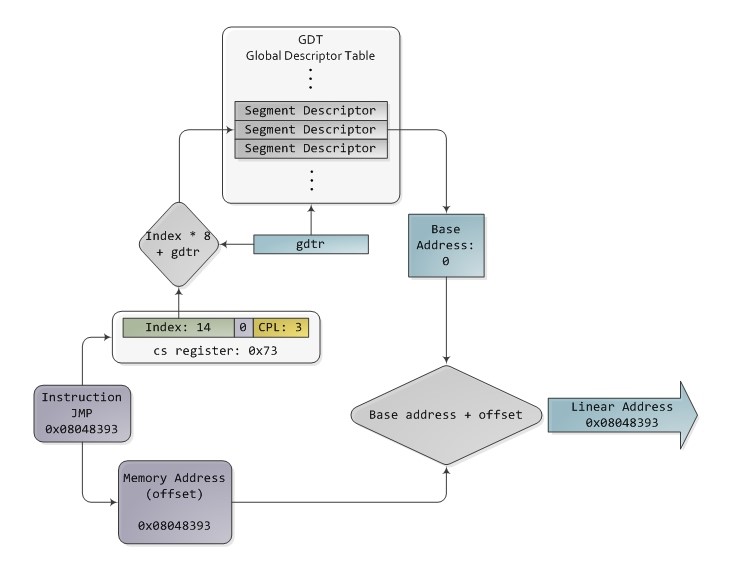
Pис. 5.8. Плоская модель сегментации
Виртуальная память в архитектуре x86
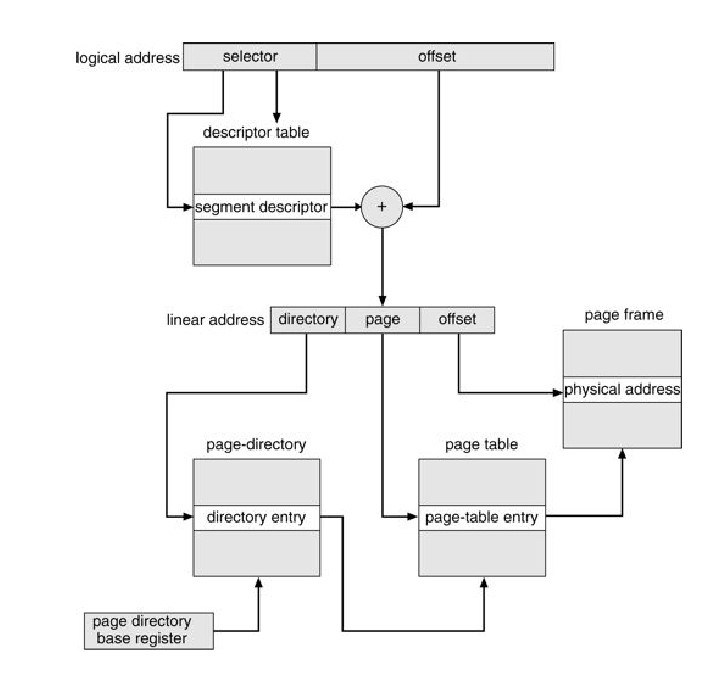
Pис. 5.9. Трансляция адреса в архитектуре x86
Системные вызовы для взаимодействия с подсистемой виртуальной памяти:
· brk, sbrk- для увеличения сегмента памяти, выделенного для данных программы
· nmap, mremap, munbap - для отображения файла или устройства в память ·
· mprotect - изменение прав доступа к областям памяти процесса
Пример выделение памяти процессу:
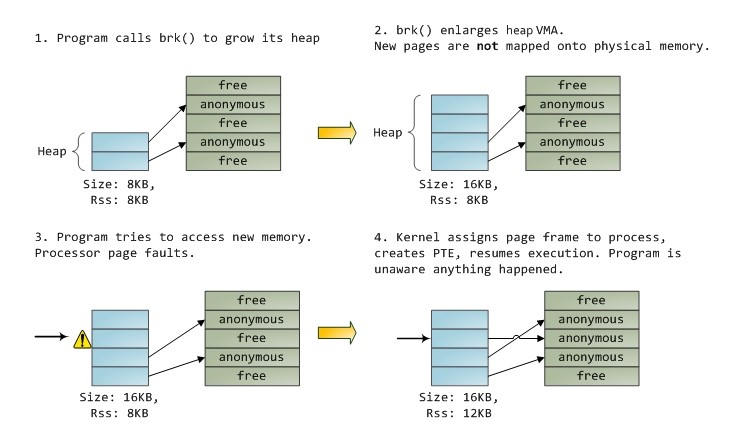
Pис. 5.10. Ленивое выделение памяти при вызове brk
Алгоритмы выделения памяти
Эффективное выделение памяти предполагает быстрое (за 1 или несколько операций) нахождение свободного участка памяти нужного размера.
Способы учета свободных участков:
· битовая карта (bitmap) — каждому блоку памяти (например, странице) ставится в соответствие 1 бит, который имеет значение занят/свободен
· связный список — каждому непрерывному набору блоков памяти одного типа (занят/свободен) ставится в соответствеи 1 запись в связном списке блоков, в которой указывается начало и размер участка
· использование нескольких связных списков для участков разных размеров
Кеширование
Кеш — это компонент компьютерной системы, который прозрачно хранит данные так, чтобы последующие запросы к ним могли быть удовлетворены быстрее. Наличие кеша подразумевает также наличие запоминающего устройства (гораздо) большего размера, в которых данные хранятся изначально. Запросы на получение данных из этого устройства проходят через кеш в том смысле, что если этих данных нет в кеше, то они запрашиваются из основного устройства и параллельно записываются в кеш. Соответственно, при последующем обращении данные могут быть извлечены уже из кеша. За счет намного меньшего размера кеш может быть сделан намного быстрее и в этом основная цель его существования.
По принципу записи данных в кеш выделяют:
· сквозной (write-through) — данные записываются синхронно и в кеш, и непосредственно в запоминающее устрйоство
· с обратной записью (write-back, write-behind) — данные записываются в кещ и иногда синхронизируются с запоминающим устройством
По принципу хранения данных выделяют:
· полностью ассоциативные
· множественно-ассоциативные
· прямого соответствия
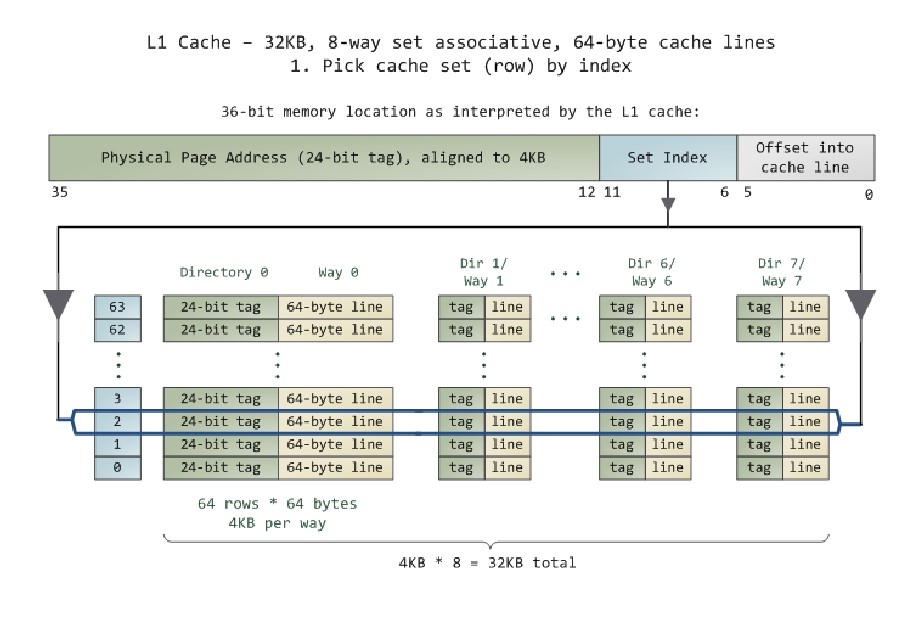
Pис. 5.11. Пример множественно-ассоциативного кеша в архитектуре х86
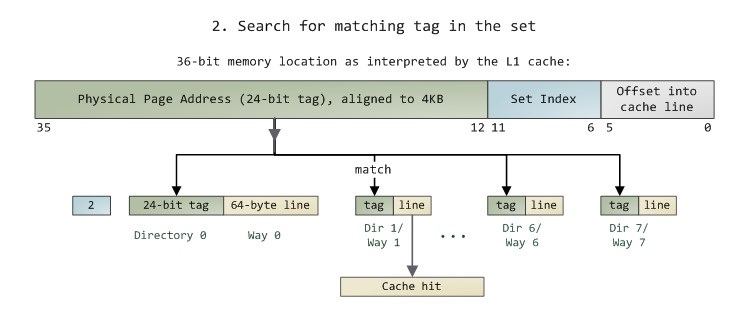
Pис. 5.12. Поиск в множественно-ассоциативном кеше
Алгоритмы замещения записей в кеше
Поскольку любой кеш всегда меньше запоминающего устройства, всегда возникает необходимость для записи новых данных в кеш удалять из него ранее записанные. Эффективное удаление данных из кеша подразумевает удаление наименее востребованных данных. В общем случае нельзя сказать, какие данные являются наименее востребованными, поэтому для этого используются эвристики. Например, можно удалять данные, к которым происходило наименьшее число обращений с момента их загрузки в кеш (least frequently used, LFU) или же данные, к которым обращались наименее недавно (least recently used, LRU), или же комбинация этих двух подходов (LRFU).
Кроме того, аппаратные ограничения по реализации кеша часто требуют минимальных расходов на учет служебной информации о ячейках, которой является также и использование данных в них. Наиболее простым способом учета обращений является установка 1 бита: было обращение или не было. В таком случае для удаления из кеша может использоваться алгоритм часы (или второго шанса), который по кругу проходит по всем ячейкам, и выгружает ячейку, если у нее бит равен 0, а если 1 — сбрасывает его в 0.
Более сложным вариантом является использование аппаратного счетчика для каждой ячейки. Если этот счетчик фиксирует число обращений к ячейке, то это простой вариант алгоритма LFU. Он обладает следующими недостатками:
· может произойти переполнение счетчика (а он, как правило, имеет очень небольшую разрядность) — в результате будет утрачена вся информация об обращениях к ячейке
· данные, к которым производилось множество обращений в прошлом, будут иметь высокое значение счетчика даже если за последнее время к ним не было обращений
Для решения этих проблем используется механизм старения, который предполагает периодический сдвиг вправо одновременно счетчиков для всех ячеек. В этом случае их значения будут уменьшаться (в 2 раза), сохраняя пропорции между собой.
Исполняемые файлы
Программа в памяти (Linux)
Выполнение программы начинается с системного вызова exec, которому передается путь к файлу с бинарным кодом программы. exec— это интерфейс к загрузчику программ ОС, который загружает секции программы в память в зависимости от формата исполняемого файла, а также выделяет дополнительные секции динамической памяти. После загрузки память программы продолжает быть разделенной на отдельные секции. Указатели на начало/конец и другие свойства каждой секции находятся в структуре mm_strict текущего процесса.
Для загрузки отдельных сегментов в память используется системный вызов mmap.
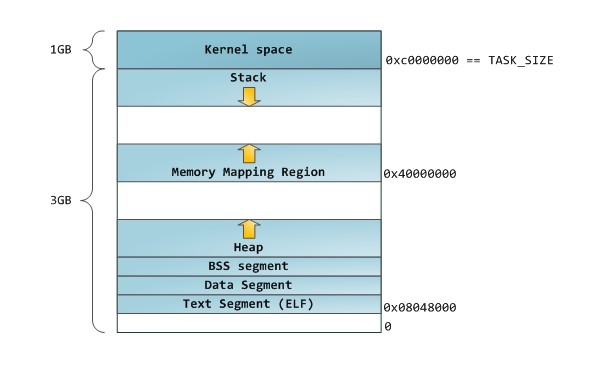
Pис. 6.1. Программа в памяти
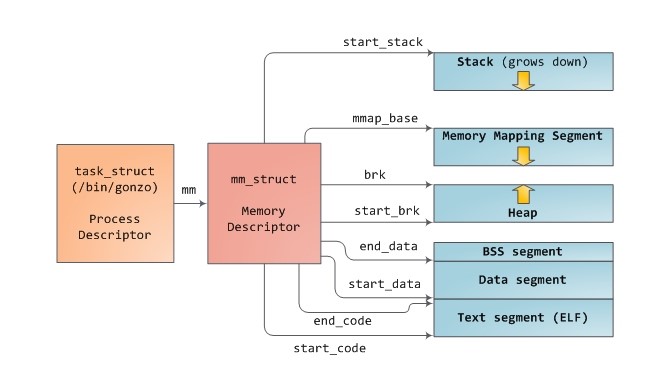
Pис. 6.2. Сегменты памяти процесса
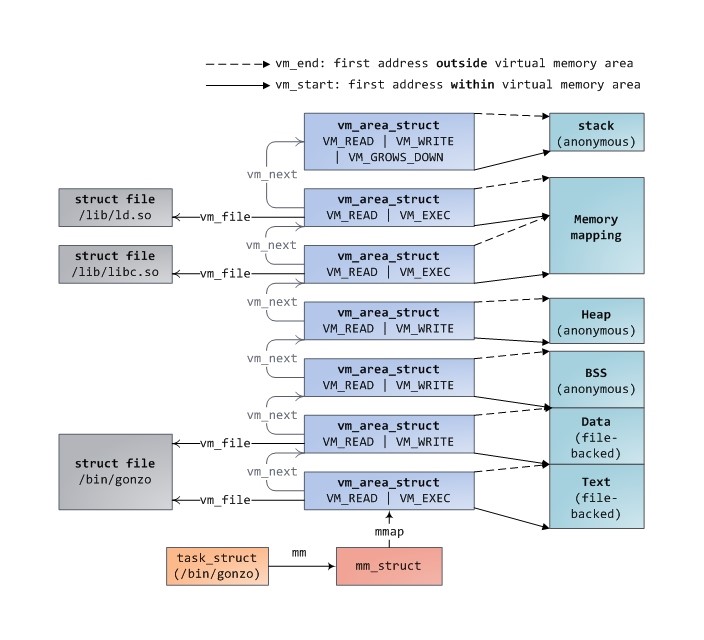
Pис. 6.3. Более подробная схема сегментов памяти процесса
Статическая память программы
Статическая память программы — это часть памяти, которая является отображением кода объектного файла программы. Она инициализируется загрузчиком программ ОС из исполняемого файла (способ инициализации зависит от конкретного формата исполняемого файла).
· Она включает несколько секций, среди которых общераспространенными являются:
· секция text — секция памяти, в которую записываются сами инструкции программы
· секция data — секция памяти, в которую записываются значения статических переменных программы
· секция bss — секция памяти, в которой выделяется место для записи значений объявленных, но не инициализированных в программе статических переменных
· секция rodata — секция памяти, в которую записываются значения констант программы
· секция таблицы символов — секция, в которой записаны все внешние (экспортируемые) символы программы с адресами их местонахождения в секциях или программы
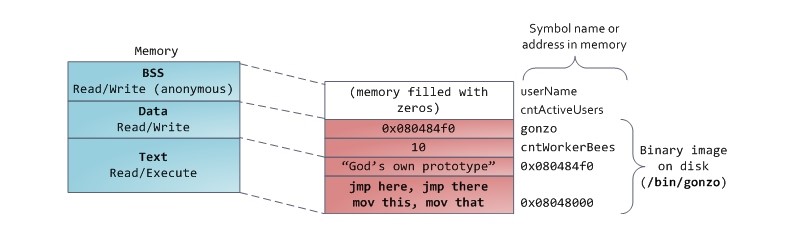
Pис. 6.4. Статическая память программы
Динамическая память выделяется программе в момент ее создания, но ее содержимое создается программой по мере ее выполнения. В области динамической памяти используется 3 стандартные секции, помимо которых могут быть и другие.
· стек(stack)
· куча (heap)
· сегмент отображаемой памяти (memory map segment)
Стек
(Более правильное название используемой структуры данных – стопка или магазин, Однако, исторически прижилось заимствованное название стек).
Стек (stack) — это часть динамической памяти, которая используется при вызове функций для хранения ее аргументов и локальных переменных. В архитектуре x86 стек растет вниз, т.е. вершина стека имеет самый маленький адрес. Регистр SP (Stack Pointer) указывает на текущую вершину стека, а регистр BP (Base Pointer) указывает на т.н. базу, которая используется для разделения стека на логические части, относящиеся к одной функции — фреймы (кадры). Помимо обычных инструкций работы с памятью и регистрами (таких как mov), дополнительно для манипуляции стеком используются инструкции push и pop, которые заносят данные на вершину стека и забирают данные с вершины. Эти инструкции также осуществляют изменение регистра .
Как правило, в программах на высокоуровневых языках программирования нет кода для работы со стеком напрямую, а это делает за кадром компилятор, реализуя определенные соглашения о вызовах функций и способы хранения локальных переменных. Однако функция alloca библиотеки stdlib позволяет программе выделять память на стеке.
Вызов функции высокоуровневого языка создает на стеке новый фрейм, который содержит аргументы функции, адрес возврата из функции, указатель на начало предыдущего фрейма, а также место под локальные переменные.
Pис. 6.5. Вид фрейма стека при вызове в рамках AMD64 ABI
В начале работы программы в стеке выделен только 1 фрейм для функции main и ее аргументов — числового значения argc и массива указателей
переменной длины argv, каждый из которых записывается на стек по отдельности, а также переменных окружения.
Pис. 6.6. Вид стека после вызова функции main
Куча
Куча (heap) — это часть динамической памяти, предназначенная для выделения участков памяти произвольного размера. Она в первую очередь используется для работы с массивами неизвестной заранее длины (буферами), структурами и объектами. Для управления кучей используется подсистема выделения памяти (memory allocator), интерфейс к которому — это функции malloc/ calloc и free в stdlib.
Основные требования к аллокатору памяти:
· минимальное используемое пространство и фрагментация
· минимальное время работы
· максимальная локальность памяти
· максимальная настраиваемость
· максимальная совместимость со стандартному
· максимальная переносимость
· обнаружение наибольшего числа ошибок
· минимальные аномалии
Многие языки высокого уровня реализуют более высокоуровневый механизм управления памятью поверх системного аллокатора — автоматическое выделение памяти со сборщиком мусора. В этом случае в программы не производится вызов функции malloc, а управление памятью осуществляет среда исполнения программы.
Варианты реализации сборки мусора:
· подсчет ссылок
· трассировка/с выставлением флагов (Mark and Sweep)
Сегмент файлов, отображаемых в память
Сегмент файлов, отображаемых в память — это отдельная область динамической памяти, которая используется для эффективно работы с файлами, а также для подключения участков памяти других программ с помощью вызова mmap.
Исполняемые файлы
В результате компиляции программы в машинный код создается исполняемый файл, т.е. файл, содержащий непосредственно инструкции процессора.
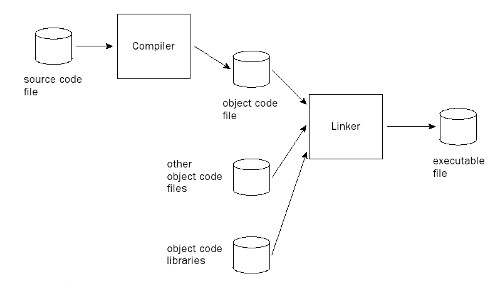
Pис. 6.7. Этапы создания исполняемого файла
Типы исполняемых файлов:
· объектный файл (object file) — файл, преобразованный компилятором, но не приведенный окончательно к виду исполняемого файла в одном из форматов исполняемых файлов
· исполняемая программа (executable) — файл в одном из форматов исполняемых файлов, который может быть запущен загрузчиком программ ОС
· разделяемая библиотека (shared library) — программа, которая не может быть запущенна самостоятельно, а подключается (компилятором) как часть других программ
· снимок содержимого памяти (core dump) — снимок состояния памяти программы в момент ее исполнения — позволяет продолжить исполнение программы с того места, на котором он был создан.
Формат исполняемых файлов
Формат исполняемых файлов — это определенная структура бинарного файла, которую формируют компилятор и компоновщик программы, и которая используется загрузчиком программ ОС.
В рамках формата исполняемых файлов описывается:
· способ задания секций файла, их количество и порядок
· метаданные, их типы и размещение в файле
· каким образом файл будет загружаться: по какому адресу в памяти, в какой последовательности
·  способ описания импортируемых и экспортируемых
способ описания импортируемых и экспортируемых
· символов ограничения на размер файла и т.п.
Распространенные форматы:
· .COM
· a.out
· COFF
· DOS MZ Executable
· Windows PE
· Windows NE
· ELF
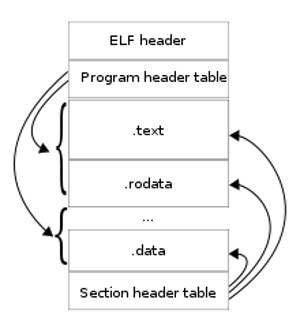
Pис. 6.8. Формат ELF
Формат ELF (Executable and Linkable Format) — стандартный формат исполняемых файлов в Linux. Файл в этом формате содержит:
· заголовок файла
· таблицу заголовков сегментов программы
· таблицу заголовков секций программы
· блоки данных
Сегменты программы содержат информацию, используемую загрузчиком программы, а секции — используемую компоновщиком.
Также в исполняемом файле может записываться отладочная информация. Некоторые форматы имеют встроенную поддержку для этого, а для некоторых форматов используются дополнения, такие как:
· stabs
· DWARF
Библиотеки
Библиотеки содержат функции, выполняющие типичные действия, которые могут использоваться другими программами. В отличие от исполняемой программы библиотека не имеет точки входа (функции main) и предназначена для подключения к другим программам или библиотекам.
Стандартная библиотека C (libc) — первая и основная библиотека любой программы на C.
Библиотеки могут подключаться к программе в момент:
· сборки - build time (такие библиотеки называются статическими)
· загрузки - load time
· исполнения - run time
Разделяемые библиотеки — это библиотеки, которые подключаются в момент загрузки или исполнения программы и могут разделяться между несколькими программами в памяти для экономии памяти. Помимо этого, они не включаются в код программы и таким образом не увеличивают его объем. С другой стороны, они в большей степени подвержены проблеме конфликта версий зависимостей разных компонент (в применении к библиотека также называемой DLL hell).
Способы подключения разделяемых библиотек в Unix:
· релокации времени загрузки программы
· позиционно-независимый код (PIC)
Релокации времени загрузки программы используют специальную секцию исполняемого файла — таблицу релокации, в которой записываются преобразования, которые нужно произвести с кодом библиотеки при ее загрузке. Ее недостатки — увеличение времени загрузки программы из-за необходимости переписывания кода библиотеки для применения всех релокаций на этом этапе, а также невозможность сделать секцию кода библиотеки, разделяемой в памяти из-за того, что релокация для каждой программы применяться по-разному, т.к. библиотека загружается в память по разным виртуальным адресам.
Позиционно-независимый код использует таблицу глобальных отступов (Global Offset Table, GOT), в которой записываются адреса всех экспортируемых символов библиотеки. Его недостаток — это замедление всех обращений к символам библиотеки из-за необходимости выполнять дополнительное обращение к GOT.
Pис. 6.9. Таблица глобальных отступов
Для поддержки позднего связывания функций через механизм "трамплина" также используется таблица компоновки процедур (Procedure Linkage Table, PLT).
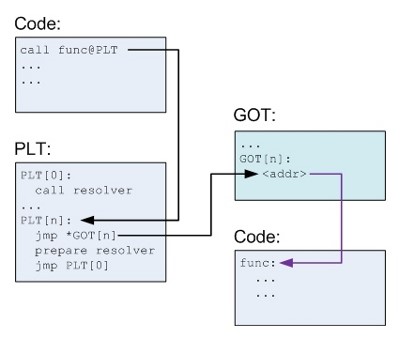
Pис. 6.10. Реализация трамплина при вызове функции с помощью таблицы компоновки процедур
Виртуальные машины
Виртуальная машина — это программная реализация реального компьютера, которая исполняет программы.
Применения виртуальных машин:
· увеличение переносимости кода
· исследование и оптимизация программ
· эмулятор
· песочница
· виртуализация
· платформа для R&D языков програмиирования
· платформа для R&D различных компьютерных систем
· сокрытие программ (вирусы)
Типы:
· системная — полная эмуляция компьютера
· процессная — частичная эмуляция компьютера для одного из процессов ОС
Системные ВМ
Виды системных ВМ:
· Гипервизор/монитор виртуальных машин: тип 1 (на голом железе) и тип 2 (на ОС-хозяине)
· Паравиртуализация
Требования Попека и Голдберга для эффективной виртуализации:
· Все чувствительные инструкции аппаратной архитектуры являются привилегированными
· Нет временных ограничений на выполнение инструкций (рекурсивная виртуализация)
Примеры: VMWare, VirtualBox, Xen, KVM, Quemu, Linux LXC containers, Solaris zones
Процессные ВМ
Процессные ВМ функционируют по принципу 1 процесс – 1 экземпляр ВМ и, как правило, предоставляют интерфейс более высокого уровня, чем аппаратная платформа.
Код программы для таких ВМ компилируется в промежуточное представление (байт-код), который затем интерпретируется ВМ. Часто в них также используется JIT-компиляция байт-кода в родной код.
Варианты реализации:
· Стек-машина (0-операнд)
· Аккумулятор-машина (1-операнд)
· Регистровая машина (2- или 3-операнд)
Примеры: JVM, .Net CLR, Parrot, LLVM, Smalltalk VM, V8
Управление процессами
Процесс
Процесс – это адресное пространство и единая нить управления. (Устаревшее определение)
Более точно понятие процесса включает в себя:
· Программу, которая исполняется
· Ее динамическое состояние (регистровый контекст, состояние памяти и т.д.)
· Доступные ресурсы (как индивидуальные для процесса, такие как дескрипторы файлов, так и разделяемые с другими)
В ОС структура Процесс (Process control block, PCB) — одна из ключевых структур данных. Она содержит всю информации о процессе, необходимую разным подсистемам ОС. Эта информация включает:
· PID (ID процесса)
· PPID (ID процесса-родителя)
· путь и аргументы, с которым запущен процесс
· программный счетчик
· указатель на стек
и др.
Ниже приведена небольшая часть этой структуры в ОС Linux:


Нить управления
Нить управления (thread) — это одна логическая цепочка выполнения команд. В одном процессе может быть, как одна нить управления, так и несколько (в системах с поддержкой многопоточности — multithreading).
ОС предоставляет интерфейс для создания нитей управления и в этом случае берет на себя их планирование наравне с планированием процессов. В стандарте POSIX описан подобный интерфейс, который реализован в библиотеке PTHREADS. Нити, предоставляемые ОС, называются родными (native).
Однако любой процесс может организовать управление нитями внутри себя независимо от ОС (фактически, в рамках одной родной нити ОС). Такой подход называют зелеными или легковесными нитями.
Волокно (fiber) — легковесная нить, которая работает в системе кооперативной многозадачности.
Преимущества родных нитей:
· не требуют дополнительных усилий по реализации
· используют стандартные механизмы планирования ОС
· блокировка и реакция на сигналы ОС происходит в рамках нити, а не всего процесса
Преимущества зеленых нитей:
· потенциально меньшие накладные расходы на создание и поддержку
· не требуют переключения контекста при системных вызовах, что дает потенциально большое быстродействие
· гибкость: процесс может реализовать любую стратегию планирования таких нитей
Виды процессов
Процессы могут запускаться для разных целей:
· выполнения каких-то одноразовых действий (например, скрипты)
· выполнения задач под управлением пользователя (интерактивные процессы, такие как редактор)
· беспрерывной работы в фоновом режиме (сервисы или демоны, такие как сервис терминала или почтовый сервер)
 Процесс-демон — это процесс, который запускается для долгосрочной работы в фоновом режиме, отключается от запустившего его терминала (его стандартные потоки ввода-вывода закрываются либо перенаправляются в лог-файл) и меняет свои полномочия на минимально необходимые.
Процесс-демон — это процесс, который запускается для долгосрочной работы в фоновом режиме, отключается от запустившего его терминала (его стандартные потоки ввода-вывода закрываются либо перенаправляются в лог-файл) и меняет свои полномочия на минимально необходимые.
Управление таким процессом, обычно, осуществляется с помощью механизма сигналов ОС.
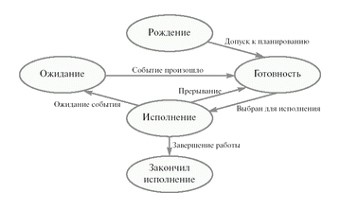
Pис. 7.1. Жизненный цикл процесса
Все процессы ОС, за исключением первого процесса, который запускается после загрузки ядра, имеют родителя. Создание нового процесса требует инициализации структуры PCB и запуска (постановки на планирование) нити управления процесса. Основным требованием к этим операциям является скорость выполнения. Инициализация структуры PCB с нуля является затратной операцией, кроме того порожденному процессу, как правило, требуется доступ к некоторым ресурсам (таким как потоки ввода-вывода) родительского процесса. Поэтому обычно структура нового процесса создается методом клонирования структуры родителя. Альтернативой является загрузка предварительно инициализированной структуры из файла и ее модификация.
Модель fork/ exec — это модель двухступенчатого порождения процесса в Unix-системах. На первой ступени с помощью системного вызова создается идентичная копия текущего процесса (для обеспечения быстродействия, как правило, через механизм копирования-при-записи copy-on-write, COW). На втором этапе с помощью операции в память созданного процесса загружается новая программа. В этой модели процесс-родитель имеет возможность дождаться завершения дочернего процесса с помощью системных вызовов семейства wait. Разбивка этой операции на два этапа дает возможность легко порождать идентичные копии процесса (например, для масштабирования приложения - такой способ применяется в сетевых серверах), а также гибко управлять ресурсами, доступными дочернему процессу.
По завершению процесс возвращает целочисленный код возврата (exit code) — результат выполнения функции main. В Unix-системах код возврата, равный 0, сигнализирует об успехе, все остальные говорят об ошибке (разработчик приложения волен произвольно сопоставлять ошибки возвращаемым значениям).
Процесс может завершиться следующим образом:
· нормально: вызвав системный вызов exit или выполнив return из функции main (что приводит к вызову exit в функции libc, которая запустила main)
· ошибочно: если выполнение процесса вызывает критическую ошибку (Segmentation Foult, General Protection Exeption, Didizion by Zero или другие аппаратные исключения)
· принудительно: если процесс завершается ОС, например, при нехватки памяти, а также, если он не обрабатывает какой-либо из посланных ему сигналов (в том числе, сигнал KILL, который невозможно обработать, из-за чего посылка этого сигнала всегда приводит к завершению процесса)
Используя функции семейства wait, один процесс может ожидать завершения другого. Это часто используется в родительских процессах, которым нужно получить информацию о завершении своих потомков, чтобы продолжить работу. Вызовы wait являются блокирующими — функция не завершится, пока не завершится процесс, которого она ждёт.
Если потомок завершается, но родительский процесс не вызывает wait, потомок становится т.н. процессом zombie. Это завершившиеся процессы, информация о завершении которых никем не запрошена. Впрочем, после завершения родительского процесса все его потомки переходят к процессу с PID 1, т.е. init. Он самостоятельно очищает информацию, оставшуюся после зомби.
Пример программы, порождающей новый процесс и ожидающей его завершения:

Работа процесса
В мультипроцессных системах все процессы исполняются на процессоре не все время своей работы, а только его часть. Соответственно, можно выделить:
· общее время нахождения процесса в системе: от момента его запуска до завершения
· (чистое) время исполнения процесса
· время ожидания
В состояние ожидания процесс может перейти либо при поступлении прерывания от процессора, либо после вызова самим процессом блокирующей операции, либо после добровольной передачи процессом управления ОС (вызов планировщика schedule при вытесняющей многозадачности либо же операция yield при кооперативной многозадачности).
При переходе процесса в состояние ожидания происходит переключение контекста и запуск на процессоре кода ядра ОС (кода обработки прерываний или кода планировщика). Переключение контекста подразумевает сохранение в памяти содержания связанных с исполняемым процессом регистров и загрузка в регистры значений для следующего процесса.
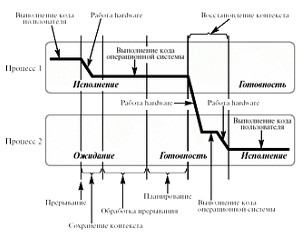
Pис. 7.2. Переключение контекста
В системах с вытесняющей многозадачностью прерывание вызывает планировщик ОС, который переводит процесс в состояние ожидания, если отведенное ему на исполнение время истекло.
Завершение блокирующих операций знаменуется прерыванием, при обработке которого ОС переводит заблокированный процесс в состояние готовности к работе.
Планирование процессов
Многозадачность — это свойство операционной системы или среды программирования обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких процессов.
Виды многозадачности:
· вытесняющая
· невытесняющая
· кооперативная (подвид невытесняющей)
Вытесняющая многозадачность подразумевает наличие в ОС специальной программы-планировщика процессов, который принимает решение о том, какой процесс должен выполняться и сколько времени отвести ему на выполнение. После завершения отведенного времени процесс принудительно прерывается и управление передается другому процессу.
При невытесняющей многозадачности процессы работают поочередно, причем переключение происходит по завершению всего процесса или логического блока в его рамках.
Кооперативная многозадачность — это вариант невытесняющей многозадачности, в которой только сам процесс может сигнализировать ОС о готовности передать управление.
Алгоритмы планирования процессов
Планирование процессов применяется в системах с вытесняющей многозадачностью.
Требования к алгоритмам планирования:
· справедливость
· эффективность (в смысле утилизации ресурсов)
· стабильность
· масштабируемость
· минимизация времени: выполнения, ожидания, отклика
Алгоритмы планирования для выбора следующего процесса на исполнение, как правило, используют приоритет процесса. Приоритет может определяться статически (один раз для процесса) или же динамически (пересчитываться на каждом шаге планирования).
Алгоритм FCFS
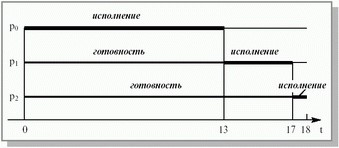
Pис. 7.3. Алгоритм FCFS
Это простой алгоритм с наименьшими накладными расходами. Это алгоритм со статическим приоритетом, в качестве которого выступает время прихода процесса. Это наименее стабильный алгоритм, который не может гарантировать приемлемое время отклика в интерактивных системах, поэтому он применяется только в системах batch-обработки.
Алгоритм Round Robin
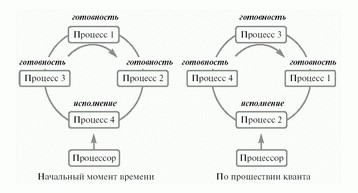
Pис. 7.4. Алгоритм Карусель
Этот алгоритм предполагает попеременное выполнение всех процессов в течение одинакового кванта времени, после завершения которого независимо от состояния процесса он прерывается и управление переходит к следующему процессу. Этот алгоритм является наиболее стабильным и простым. Он вообще не использует приоритет процесса.
Алгоритм справедливого планирования
В основе этого алгоритма лежит принцип: из всех кандидатов на выполнение должен выбираться тот, у которого отношение чистого времени фактической работы к общему времени нахождения в системе наименьший. Иными словами, этот алгоритм использует динамический приоритет, который
вычисляется по формуле P= t/T (где t- чистое время исполнения, T - время прошедшее от запуска процесса; чем меньше значение P, тем приоритет выше).
Алгоритм Многоуровневая очередь с обратной связью
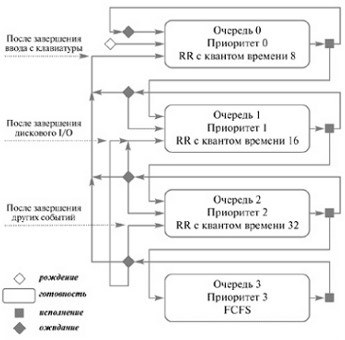
Pис. 7.5. Алгоритм Многоуровневая очередь с обратной связью
В качестве примера более сложного адаптивного алгоритма могут служить многоуровневые очереди с обратной связью, которые принимают решение о приоритете процесса на основе времени, которое необходимо ему для завершения работы или текущего логического блока.
Реальные алгоритмы
Алгоритмы, применяемые в реальных системах, делятся на алгоритмы для интерактивных систем и алгоритмы для систем реального времени. Алгоритмы для систем реального времени всегда имеют ограничения на время завершения отдельных операций, поэтому им для планирования необходима дополнительная информация, которой, как правило, нет в интерактивных системах — например, время до завершения процесса.
В основе реальных алгоритмов лежат базовые алгоритмы, перечисленные выше, но также они используют некоторые дополнительные параметры такие как:
· эпохи (временные интервалы, в конце которых накопленная для планирования информация сбрасывается)
· группировку процессов по классам (мягкого реального времени, процессы ядра, интерактивные, фоновые и т.д.) для обеспечения лучшего времени отклика системы
Кроме того, в таких системах учитываются технологии Симметричный мультипроцессинг (Symmetrical Multiprocessing, SMP) и Одновременная многопоточность (Symulteneous Multithreading, SMT), при которых несколько ядер процессора или несколько логических потоков исполнения в процессоре работают с общей памятью.
Межпроцессное взаимодействие
Цели взаимодействия
· модульность (путь Unix: маленькие кусочки, слабо связанные между собой, которые делают что-то одно и делают это очень хорошо)
· масштабирование
· совместное использование данных
· разделение привилегий
· удобство
Типы взаимодействия
· через разделяемую память
· обмен сообщениями
· сигнальный
· канальный
· широковещательный
Взаимодействие через разделяемую память
Самый быстрый и простой способ взаимодействия, при котором процессы записывают и считывают данные из общей области памяти. Он не требует никаких накладных расходов, но подразумевает наличие договоренности о формате записываемых данных. Проблемы этого подхода:
· необходимость блокирующей синхронизации для обеспечения неконфликтного доступа к общей памяти
· увеличение логической связности между отдельными процессами
· не возможность масштабироваться за рамками памяти одного компьютера
Обмен сообщениями
Передача сообщений обладает прямо противоположными свойствами и считается более предпочтительным способом организации взаимодействия в общем случае. Сообщения могут передаваться как индивидуально, так и в рамках выделенной сессии обмена сообщениями.
Сигнальный способ
Сигнальный способ — это вариант взаимодействия через передачу сообщений, который предполагает возможность отправки только заранее предопределенных сигналов, которые не имеют никакой нагрузки в виде данных. Таким образом сигналы могут передавать информацию только о предварительно заданном наборе событий. Такая система является простой, но не способна обслуживать все варианты взаимодействия. Поэтому она часто применяется для обслуживания критических сценариев работы.
Системный вызов KILL позволяет посылать сигналы процессам Unix. Среди них есть зарезервированные сигналы, такие как:
· TERM- запрос на завершение процесса
· HUP- запрос на перезапуск процесса
· ABRT- запрос на отмену текущей операции (генерируется ОС при нажатии Ctrl+C)
· PIPE - сигнал о закрытии конвейера другим процессом
· KILL- сигнал о принудительном завершении процесса
и др.
Процес в Unix обязан обработать пришедший ему сигнал, иначе ОС принудительно завершает его работу.
Канальный способ взаимодействия
Канальный способ — это вариант взаимодействия через передачу сообщений, при котором между процессами устанавливается канал соединения, в рамках которого передаются сообщения. Этот канал может быть, как односторонним (сообщения идут только от одного процесса к другому), так и двусторонним.
Pipe (конвейер, анонимный канал) — односторонний канал, который позволяет процессам передавать данные в виде потока байт. Это самый простой способ
взаимодействия в Unix, имеющий специальный синтаксис в командных оболочках (proc1 | proc2, что означает, что данные из процесса proc1 передаются в proc2). Анонимный канал создается системным вызовом pipe, который принимает на вход массив из двух чисел и записывает в них два дескриптора (один из них открыт на запись, а другой — на чтение).
Особенности анонимных каналов:
· данные передаются построчно
· не задан формат сообщений, т.е. процессы сами должны "договариваться" о нем
· ошибка в канале приводит к посылке сигнала pipe к процессу, который пытался выполнить чтение или запись в него
Именованный канал (named pipe) создается с помощью системного вызова mkfifo. Фактически, он является правильным заменителем для обмена данными через временные файлы, поскольку тот обладает следующими недостатками:
· использование медленного диска вместо более быстрой памяти
· расход места на диске (в то время как при обмене данными через FIFO после считывания они стираются); более того, место на диске может закончиться
· у процесса может не быть прав создать файл или же файл может быть испорчен/удален другим процессом
Модель акторов
Модель акторов Хьювита — это теоретическая модель, исследующая взаимодействие независимых программных агентов.
Актор — это независимый легковесный процесс, который взаимодействует с другими процессами только через передачу сообщений. В этой модели процессы не используют разделяемую память.
Эта модель лежит в основе языка программирования Erlang, а также библиотека для организации распределенной работы Java-приложений Akka.
Синхронизация
Проблемы синхронизации
Синхронизация в компьютерных системах — это координация работы процессов таким образом, чтобы последовательность их операций была предсказуемой. Как правило, синхронизация необходима при совместном
доступе к разделяемым ресурсам. Критическая секция (critical section) — часть программы, в которой есть обращение к совместно используемым данным. При нахождении в критической секции двух (или более) процессов, возникает состояние гонки/состязания за ресурсы. Состояние гонки (race condition) — это состояние системы, при котором результат выполнения операций зависит от того, в какой последовательности будут выполняться отдельные процессы в этой системе, но управлять этой последовательностью нет возможности. Иными словами, это противоположность правильной синхронизации.
Для избегания гонок необходимо выполнение таких условий:
· два процесса не должны одновременно находиться в одной критической области
· процесс, находящийся вне критической области, не может блокировать другие процессы
· невозможна ситуация, в которой процесс вечно ждет попадания в критическую область
· Также в программе, в общем случае, не должно быть предположений о скорости или количестве процессоров
Пример условий гонок

Поскольку процессор не может модифицировать значения в памяти непосредственно, для этого ему нужно загрузить значение в регистр, изменить его, а затем снова выгрузить в память. Если в процессе выполнения этих трех инструкций процесс будет прерван, может возникнуть непредсказуемый результат, т.е. имеет место условие гонки.
Классические задачи синхронизации — это модельные задачи, на которых исследуются различные ситуации, которые могут возникать в системах с разделяемым доступом и конкуренцией за общие ресурсы. К ним относятся задачи: Производитель-потребитель, Читатели-писатели, Обедающие философы, Спящий парикмахер, Курильщики сигарет, Проблема Санта-Клауса и др.
Задача Производитель-потребитель (также известна как задача ограниченного буфера): 2 процесса — производитель и потребитель — работают с общим ресурсом (буфером), имеющим максимальный размер N. Производитель записывает в буфер данные последовательно в ячейки 0,1,2,..., пока он не заполниться, а потребитель читает данные из буфера в обратном порядке, пока он не опустеет. Запись и считывание не могут происходить одновременно.
Проблема синхронизации в этом варианте: если производитель будет прерван
потребителем после того, как запишет данные в буфер, но до того, как увеличит счетчик, то потребитель считает из буфера элемент перед только что записанным, т.е. в буфере образуется дырка. После того как производитель таки увеличит счетчик, счетчик как раз будет указывать на эту дырку. Симметричная проблема есть и у потребителя.
Также у этой задачи может быть множество модификаций: например, количество производителей и потребителей может быть больше 1. В этом случае добавляются новые проблемы синхронизации.
Еще одна проблема этого решения — это бессмысленная трата вычислительных ресурсов: циклы — т.н. занятое ожидание(busy loop, busy waiting) или же поллинг (pooling) — это ситуация, когда процесс не выполняет никакой полезной работы, но занимает процессор и не дает в это время работать на нем другим процессам. Таких ситуаций нужно по возможности избегать.
Алгоритмы программной синхронизации
Программный алгоритм синхронизации — это алгоритм взаимного исключения, который не основан на использовании специальных команд процессора для запрета прерываний, блокировки шины памяти и т. д. В нем используются только общие переменные памяти и цикл для ожидания входа в критическую секцию исполняемого кода. В большинстве случаев такие алгоритмы не эффективны, т.к. используют поллинг для проверки условий синхронизации.
Пример программного адгоритма — алгоритм Петерсона.
Аппаратные алгоритмы синхронизации
Аппаратные инструкции синхронизации реализуют атомарные примитивные операции, на основе которых можно строить механизмы синхронизации более высокого уровня. Атомарность означает, что вся операция выполняется как целое и не может быть прервана посредине. Атомарные примитивные операции для синхронизации, как правило, выполняют вместе 2 действия: запись значения и проверку предыдущего значения. Это дает возможность проверить условие и сразу записать такое значение, которое гарантирует, что условие больше не будет выполняться.
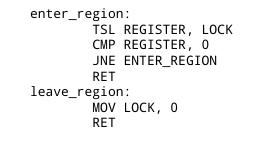
Try-and-set lock (TSL)
Инструкции типа try-and-set записывают в регистр значение из памяти, а в память — значение 1. Затем они сравнивают значение в регистре с 0. Если в памяти и был 0 (т.е. доступ к критической области был открыт), то сравнение пройдет успешно, и в то же время в память будет записан 1, что гарантирует, что в следующий раз сравнение уже не будет успешным, т.е. доступ закроется.
Реализация критической секции с помощью TSL:
То же самое на С:

Compare- and – swap ( CAS)
Инструкции типа compare-and-swap записывают в регистр новое значение и
при этом проверяют, что старое значение в регистре равно запомненному ранее значению.
В x86 называется CMPXCHG.
Аналог на С:

Проблема ABA (ABBA): CAS инструкции не могут отследить ситуацию, когда значение в регистре было изменено на новое, а потом снова было возвращено к предыдущему значению. В большинстве случаев это не влияет на работу алгоритма, а в тех случаях, когда влияет, необходимо использовать инструкции с проверкой на такую ситуацию, такие как LL/SC.
Другие аппаратные инструкции
· Двойной CAS
· Fetch-and-add
· Load-link/store-conditional (LL/SC)
Системные механизмы синхронизации
С помощью аппаратных инструкций можно реализовать более высокоуровневые конструкции, которые могут ограничивать доступ в критическую область, а также сигнализировать о каких-то событиях.
Самым простым вариантом ограничения доступа в критическую область является переменная-замок: если ее значение равно 0, то доступ открыт, а если 1 — то закрыт. У нее есть 2 атомарные операции:
· заблокировать (lock) — проверить, что значение равно 0, и устанавливает его в 1 или же ждать, пока оно не станет 0
· разблокировать (unlock), которая устанавливает значение в 1
Также полезной может быть операция попробовать заблокировать (trylock), которая не ждет пока значение замка станет 0, а сразу возвращает ответ о невозможности заблокировать замок.
Спинлок
Спинлок — это замок, ожидание при блокировке которого реализовано в виде занятого ожидания, т.е. поток "крутится" в цикле, ожидая разблокировки замка.
Использование спинлока целесообразно только в тех областях кода, которые не могут вызвать блокировку, иначе все время, отведенное планировщиком потоку, ожидающему на спинлоке, будет потрачено на ожидание и при этом другие потоки не будут работать.
Семафоры
Семафор — это примитив синхронизации, позволяющий ограничить доступ к критической секции только для N потоков. При этом, как правило, семафор позволяет реализовать это без использования занятого ожидания.
Концептуально семафор включает в себя счетчик и очередь ожидания для потоков. Интерфейс семафора состоит из двух основных операций: опустить (down) и поднять (up). Операция опустить атомарно проверяет, что счетчик больше 0 и уменьшает его. Если счетчик равен 0, поток блокируется и ставиться в очередь ожидания. Операция поднять увеличивает счетчик и посылает ожидающим потокам сигнал пробудиться, после чего один из этих потоков сможет повторить операцию опустить.
Мьютекс (Mutex)
Мьютекс — от словосочетания mutual exclusion, т.е. взаимное исключение — это примитив синхронизации, напоминающий бинарный семафор с дополнительным условием: разблокировать его должен тот же поток, который и заблокировал.
Стоит отметить, что не все системы предоставляют гарантии того, что мьютекс будет разблокирован именно заблокировавшим его потоком. В приведенном выше примере это условие как раз не проверяется.
Мьютекс с возможностью повторного входа (re-entrant mutex) — это мьютекс, который позволяет потоку несколько раз блокировать его.
Переменные условия и мониторы
Монитор — это механизм синхронизации в объектно-ориентированном программировании, при использовании которого объект помечается как синхронизированный и компилятор добавляет к вызовам всех его методов (или только выделенных синхронизированных методов) блокировку с помощью мьютекса. При этом код, использующий этот объект, не должен заботиться о синхронизации. В этом смысле монитор является более высокоуровневой конструкцией, чем семафоры и мьютексы.
Переменная условия (condition variable) — примитив синхронизации,
позволяющий реализовать ожидание какого-то события и оповещение о нем. Над ней можно выполнять такие действия:
· ожидать (wait) сообщения о каком-то событии
· сигнализировать событие всем потокам, ожидающим на данной переменной. Сигнализация может быть блокирующей (signal) — в этом случае управление переходит к ожидающему потоку— и неблокирующей (notify) — в этом случае управление остается у сигнализирующего потока
Большинство мониторов поддерживают внутри себя использование переменных условия. Это позволяет нескольким потоком заходить в монитор и передавать управление друг другу через эту переменную.
Интерфейс синхронизации
POSIX Threads (Pthreads) — это часть стандарта POSIX, которая описывает базовые примитивы синхронизации, поддерживаемые в Unix системах. Эти примитивы включают семафор, мьютекс и переменные условия.
Futex (быстрый замок в пользовательском пространстве) — это реализация мьютекса в Unix-системах, которая оптимизирована для минимального использования функций ядра ОС, за счет чего достигается более быстрая работа с ним. С помощью фьютексов в Linux реализованы семафоры и переменные условия.
Над фьютексами можно делать такие базовые операции:
· ожидать —wait(addr,val)— проверяет, что значение по адресу addr равно val, и, если это так, то переводит поток в состояние ожидания, а иначе продолжает работу (т.е. входит в критическую область)
· разбудить —wake (addr,n)— посылает потокам, ожидающих на фьютексе по адресу addr оповещение о необходимости проснуться
Проблемы синхронизации
Помимо условий гонки и занятого ожидания неправильная синхронизация может привести к следующим проблемам:
Тупик/взаимоблокировка (deadlock) — ситуация, когда 2 или более
потоков ожидают разблокировки замков друг от друга и не могут продвинуться. Простейший пример кода, который может вызвать взаимную блокировку:

Живой блок (livelock) — ситуация с более, чем двумя потоками, при которой потоки ожидают разблокировки друг от друга, при этом могут менять свое состояние, но не могут продвинуться глобально в своей работе. Такая ситуация более сложная, чем тупик и возникает значительно реже: как правило, она связанна с временными особенностями работы программы.
Инверсия приоритета — ситуация, когда более поток с большим приоритетом вынужден ожидать потоки с меньшим приоритетом из-за неправильной синхронизации.
Голодание — ситуация, когда поток не может получить доступ к общему ресурсу и не может продвинуться. Такая ситуация может быть следствием как тупика, так и инверсии приоритета.
Способы предотвращения тупиков
Все способы борьбы с тупиками не являются универсальными и могут работать только при определенных условиях. К ним относятся:
· монитор тупиков, который следит за тем, чтобы ожидание на каком-то из замков не длилось слишком долго, и рестартует ожидающий поток в таком случае
· нумерация замков и их блокировка только в монотонном порядке
· Алгоритм банкира
Неблокирующая синхронизация
Неблокирующая синхронизация — это группа подходов, которые ставят своей целью решить проблемы синхронизации альтернативным путем без явного использования замков и основанных на них механизмов. Эти подходы создают новую конкурентную парадигму программирования, что можно сравнить с появлением структурной парадигмы как отрицанием подхода к написанию программ с использованием низкоуровневой конструкции goto и перехода к использованию структурных блоков: итерация, условное выражение, цикл.
Ничего общего
Архитектуры программ без общего состояния рассматривают вопросы построения систем из взаимодействующих компонент, которые не имеют разделяемых ресурсов и обмениваются информацией только через передачу сообщений. Такие системы, как правило, являются намного менее связными, и поэтому лучше поддаются масштабированию и являются менее чувствительными к отказу отдельных компонент.
Теоретические работы на этот счет: Взаимодействующие параллельные процессы (Communicating Parallel Processes, CPP) и модель Акторов. Практическая реализация этой концепции — язык Erlang. В этой модели единицей вычисления является легковесный процесс, который имеет "почтовый ящик", на который ему могут отправляться сообщения от других процессов, если они знают его ID в системе. Отправка сообщений является неблокирующей (асинхронной), а прием является синхронным: т.е. процесс может заблокироваться в ожидании сообщения. При этом время блокировки может быть ограниченно программно.
CSP
Взаимодействующие последовательные процессы (Communicating Sequential Processes, CSP) — это еще один подход к организации взаимодействия без использования замков. Единицами взаимодействия в этой модели являются процессы и каналы. В отличие от модели CPP, пересылка данных через канал в этой модели происходит, как правило, синхронно, что дает возможность установить определенную последовательность выполнения процессов. Данная концепция реализована в языке программирования Go.
Программная транзакционная память
Транзакция — это группа последовательных операций, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта. В теории баз данных существует концепция ACID, которая описывает условия, которые накладываются на транзакции, чтобы они имели полезную семантику.
A означает атомарность — транзакция должна выполняться как единое целое. C означает целостность (consistency) — в результате транзакции будут либо изменены все данные, с которыми работает транзакция, либо никакие из них. I означает изоляция — изменения данных, которые производятся во время транзакции, станут доступны другим процессам только после ее завершения. D означает сохранность — после завершения транзакции система БД гарантирует, что ее результаты сохраняться в долговременном хранилище данных. Эти свойства, за исключением, разве что, последнего могут быть применимы не только к БД, но и к любым операциям работы с данными. Программная система, которая реализует транзакционные механизмы для работы с разделяемой памятью — это Программная транзакционная память (Software Transactional Memory, STM). STM лежит в основе языка программирования Clojure, а также доступна в языках Haskell, Python (в реализации PyPy) и других.
Файловая система
Дата добавления: 2021-05-18; просмотров: 703; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!