Концептуальные и физические ER-модели
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы. Это означает, что диаграмма не учитывает особенности конкретной СУБД. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведенной на Рис. 9 может выглядеть, например, следующим образом:

Рис. 10
На данной диаграмме каждая сущность представляет собой таблицу базы данных, каждый атрибут становится колонкой соответствующей таблицы. Обращаем внимание на то, что во многих таблицах, например, "CUST_DETAIL" и "PROD_IN_SKLAD", соответствующих сущностям "Запись списка накладной" и "Товар на складе", появились новые атрибуты, которых не было в концептуальной модели - это ключевые атрибуты родительских таблиц, мигрировавших в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
Легко заметить, что полученные таблицы сразу находятся в 3НФ.
Выводы
Реальным средством моделирования данных является не формальный метод нормализации отношений, а так называемое семантическое моделирование.
В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship).
Диаграммы сущность-связь позволяют использовать наглядные графические обозначения для моделирования сущностей и их взаимосвязей.
|
|
|
Различают концептуальные и физические ER-диаграммы. Концептуальные диаграммы не учитывают особенностей конкретных СУБД. Физические диаграммы строятся по концептуальным и представляют собой прообраз конкретной базы данных. Сущности, определенные в концептуальной диаграмме становятся таблицами, атрибуты становятся колонками таблиц (при этом учитываются допустимые для данной СУБД типы данных и наименования столбцов), связи реализуются путем миграции ключевых атрибутов родительских сущностей и создания внешних ключей.
При правильном определении сущностей, полученные таблицы будут сразу находиться в 3НФ. Основное достоинство метода состоит в том, модель строится методом последовательных уточнений первоначальных диаграмм.
В данной главе, являющейся иллюстрацией к методам ER-моделирования, не рассмотрены более сложные аспекты построения диаграмм, такие как подтипы, роли, исключающие связи, непереносимые связи, идентифицирующие связи и т.п.
Графическая нотация модели: диаграммы "сущность-связь"
Типичной формой документирования логической модели предметной области при ER-моделировании являются диаграммы "сущность-связь", или ER-диаграммы (Entity Relationship Diagram). ER-диаграмма позволяет графически представить все элементы логической модели согласно простым, интуитивно понятным, но строго определенным правилам — нотациям.
|
|
|
Для создания ER диаграмм обычно используют одну из двух наиболее распространенных нотаций.
· Integration DEFinition for Information Modeling (IDEF1X). Эта нотация была разработана для армии США и стала федеральным стандартом США. Кроме того, она является стандартом в ряде международных организаций (НАТО, Международный валютный фонд и др.).
· Information Engineering (IE). Нотация, разработанная Мартином (Martin), Финкельштейном (Finkelstein) и другими авторами, используется преимущественно в промышленности.
Построение ER-диаграмм, как правило, ведется с использованием CASE-средств. В данной лекции во всех примерах, если это не оговорено особо, будет использоваться нотация MS Office Visio 2007.
Сущность на ER-диаграмме представляется прямоугольником с именем в верхней части ( рис. 6.3).

Рис. 6.3. Представление сущности "Сотрудник" на ER-диаграмме
В прямоугольнике перечисляются атрибуты сущности, при этом атрибуты, составляющие уникальный идентификатор сущности, подчеркиваются ( рис. 6.4).
|
|
|

Рис. 6.4. Представление сущности "Сотрудник" с атрибутами и уникальным идентификатором сущности
Каждый экземпляр сущности должен быть уникальным и отличаться от других атрибутов. Одним из основных компьютерных способов распознавания сущностей в ИС является присвоение сущностям идентификаторов (entity identifier). Поскольку сущность определяется набором своих атрибутов, для каждой сущности целесообразно выделить такое подмножество атрибутов, которое однозначно идентифицирует данную сущность. Часто идентификатор сущности называют первичным ключом (primary key).
Первичный ключ (primary key) – это атрибут или группа атрибутов, однозначно идентифицирующая экземпляр сущности. Атрибуты первичного ключа на диаграмме не требуют специального обозначения – это те атрибуты, которые находятся в списке атрибутов выше горизонтальной линии ( рис. 6.3).
Выбор первичного ключа может оказаться непростой задачей, решение которой в состоянии повлиять на эффективность будущей ИС. В одной сущности могут оказаться несколько атрибутов или наборов атрибутов, претендующих на роль первичного ключа. Такие претенденты называются потенциальными ключами (candidate key).
|
|
|
Ключи могут быть сложными, т.е. содержащими несколько атрибутов. Сложные первичные ключи не требуют специального обозначения – это список атрибутов выше горизонтальной линии.
Рассмотрим кандидатов на первичный ключ сущности "сотрудник" ( рис. 6.5).

Рис. 6.5. Определение первичного ключа для сущности "сотрудник"
Здесь можно выделить следующие потенциальные ключи.
1. Табельный номер.
2. Номер паспорта.
3. Фамилия + Имя + Отчество.
Для того чтобы стать первичным, потенциальный ключ должен удовлетворять ряду требований.
Уникальность. Два экземпляра не должны иметь одинаковых значений возможного ключа. Потенциальный ключ ( Фамилия + Имя + Отчество ) является плохим кандидатом, поскольку в организации могут работать полные тезки.
Компактность. Сложный возможный ключ не должен содержать ни одного атрибута, удаление которого не приводило бы к утрате уникальности. Для обеспечения уникальности ключа ( Фамилия + Имя + Отчество ) дополним его атрибутами Дата рождения и Цвет глаз. Если бизнес-правила говорят, что сочетания атрибутов Фамилия + Имя + Отчество + Дата рождения достаточно для однозначной идентификации сотрудника, то Цвет глаз оказывается лишним, т. е. ключ Фамилия + Имя + Отчество + Дата рождения + Цвет глаз не является компактным.
При выборе первичного ключа предпочтение должно отдаваться более простым ключам, т. е. ключам, содержащим меньшее количество атрибутов. В примере ключи № 1 и № 2 предпочтительней ключа № 3.
Атрибуты ключа не должны содержать нулевых значений. Если допускается, что сотрудник может не иметь паспорта или вместо паспорта иметь какое-либо другое удостоверение личности, то ключ № 2 не подойдет на роль первичного ключа. Если для обеспечения уникальности необходимо дополнить потенциальный ключ дополнительными атрибутами, то они не должны содержать нулевых значений. При дополнении ключа № 3 атрибутом Дата рождения нужно убедиться в том, что даты рождения известны для всех сотрудников.
Значение атрибутов ключа не должно меняться в течение всего времени существования экземпляра сущности. Сотрудница организации может выйти замуж и сменить как фамилию, так и паспорт. Поэтому ключи № 2 и 3 не подходят на роль первичного ключа.
Каждая сущность должна иметь, по крайней мере, один потенциальный ключ. Многие сущности имеют только один потенциальный ключ. Такой ключ становится первичным. Некоторые сущности могут иметь более одного возможного ключа. Тогда один из них становится первичным, а остальные – альтернативными ключами. Альтернативный ключ (Alternate Key) – это потенциальный ключ, не ставший первичным.
Некоторые сущности имеют естественные (натуральные) ключи. Например, естественным идентификатором счета-фактуры является его номер. В противном случае проектировщик может создать суррогатный ключ (Surrogate Key) – атрибут, значение которого создается искусственно и не имеет отношения к предметной области. При моделировании структур данных для ХД суррогатные ключи во многих ситуациях являются более предпочтительными.
Домены назначаются аналитиками и фиксируются в специальном документе — словаре данных (Data Dictionary). При создании логической модели домены могут быть специфицированы в сущностях на ER-диаграмме.
Каждый атрибут имеет домен. Домен можно определить как абстрактный атрибут, на основе которого можно создавать обычные атрибуты, при этом создаваемые атрибуты будут иметь все свойства домена-прародителя. Каждый атрибут может быть определен только на одном домене, но на каждом домене может быть определено множество атрибутов. В понятие домена входит не только тип данных, но и область значений данных. Например, можно определить домен "Возраст" как положительное целое число и определить атрибут Возраст сотрудника как принадлежащий этому домену.
На уровне логического моделирования данных назначение домена атрибуту носит общий характер. Например, атрибут текстовый, числовой, бинарный, дата или "не определен". В последнем случае аналитик должен дать описание домена. На последующих стадиях тип доменаконкретизируется, смысл понятия домена в физической модели ХД уже, чем его может понимать аналитик. Это связано с тем, что в рамках физической модели домен реализуется посредством механизма ограничения домена, СУБД не понимает неопределенных доменов.
Проектировщик должен тщательным образом изучить домены каждого атрибута с точки зрения их реализуемости в СУБД, с участием аналитиков внести в них изменения, если условие реализуемости не выполняется. При этом проектировщик руководствуется следующим:
· для реализации реляционного ХД требуется использовать реляционную или объектно-реляционную СУБД, например, MS SQL Server 2008;
· в большинстве реляционных СУБД в качестве языка манипулирования и описания данных используется SQL, поддерживающий определенные стандарты, например, ANSI SQL-92.
Отношение (связь) сущностей на ER-диаграмме изображается линией, соединяющей эти сущности. Отношение читается вдоль линии либо слева направо, либо справа налево. На рис. 6.6 представлено следующее отношение: каждая специальность по образованию должна быть зарегистрирована за определенным физическим лицом (персоной), физическое лицо может иметь одну или более специальностей по образованию.

Рис. 6.6. Представление отношения между двумя сущностями на ER-диаграмме
В MS Office Visio имя связи, степень связи (мощность) и класс принадлежности сущности к связи определяется на вкладке "Свойства базы данных", как показано на рис. 6.7. Стрелка на линии связи указывает на родительскую таблицу.

увеличить изображение
Рис. 6.7. Определение мощности связи отношения между сущностями "Сотрудник" и "Образование"
При выделении связей акцент делается на выявление их характеристик. Связь представляет собой взаимоотношение между двумя или более сущностями. Каждая связь реализуется через значения атрибутов сущностей, например, экземпляр сущности "Сотрудник" ( рис. 6.6) связан с экземпляром сущности "Образование" по одинаковым значениям атрибутов Табельный номер. Другими словами, при создании связи в одной из сущностей, называемой дочерней сущностью, создается новый атрибут, называемый внешним ключом (Foreign Key, FK) (на рис. 6.6 это атрибут Табельный номер ). Иногда атрибуты внешнего ключа обозначаются символом (FK) после своего имени.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой Имя связи (Verb Phrase) – фраза, характеризующая отношение между родительской и дочерней сущностями. Имя связи выражает некоторое ограничение или бизнес-правило и облегчает чтение диаграммы. На рис. 6.8 показано присвоение связи имени.

увеличить изображение
Рис. 6.8. Именование связи между сущностями "Сотрудник" и "Образование"
Существуют различные типы связей: идентифицирующая связь (identifying relationship) "один ко многим", связь "многие ко многим" и неидентифицирующая связь (non-identifying relationship) "один ко многим". С типами связей связывают и различные типы сущностей.
Различают два типа сущностей: зависимые (Dependent entity) и независимые (Independent entity). Тип сущности определяется ее связью с другими сущностями. Идентифицирующая связь устанавливается между независимой (родительский конец связи) и зависимой (дочерний конец связи) сущностями.
Экземпляр зависимой сущности определяется только через отношение к родительской сущности, т. е. в структуре на рис. 6.8 информация о специальности не может быть внесена и не имеет смысла без информации о сотруднике, который имеет специальность по диплому об образовании. При установлении идентифицирующей связи (на рисунке непрерывная линия) атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности (непрерывная линия). Эта операция дополненияатрибутов дочерней сущности при создании связи называется миграцией атрибутов. В дочерней сущности такой атрибут считается внешним ключом.
Если модель создается при помощи CASE-средств, то при генерации схемы БД атрибуты первичного ключа получат признак NOT NULL, что означает невозможность внесения записи в таблицу "Сотрудники" без информации о табельном номере сотрудника.
При установлении неидентифицирующей связи ( рис. 6.9, пунктирная линия) дочерняя сущность остается независимой, а атрибуты первичного ключа родительской сущности мигрируют в состав неключевых компонентов родительской сущности. Неидентифицирующая связь служит для связывания независимых сущностей ( рис. 6.9).

увеличить изображение
Рис. 6.9. Неидентифицирующая связь
Экземпляр сущности "Сотрудник" может существовать безотносительно к какому-либо экземпляру сущности "Отдел", т. е. сотрудник может работать в организации и не числиться в каком-либо отделе.
Идентифицирующая связь показывается на диаграмме сплошной линией с жирной точкой на дочернем конце связи (см. рис. 6.8), неидентифицирующая – пунктирной (см. рис. 6.9).
Связь "многие ко многим" (many-to-many relationship) может быть создана только на уровне логической модели. На рис. 6.10 показан пример определения связи "многие ко многим". Врач может принимать много пациентов, пациент может лечиться у нескольких врачей. Такая связь обозначается сплошной линией с двумя стрелочками на концах.
Связь "многие ко многим" должна именоваться двумя фразами – в обе стороны (в примере "принимает/лечится"). Это облегчает чтение диаграммы. Связь на рис. 6.10 следует читать так: Врач <принимает> Пациента, Пациент <лечится> у Врача.

увеличить изображение
Рис. 6.10. Связь "многие ко многим"
Как было указано выше, связи определяют, является ли сущность независимой или зависимой. Различают несколько типов зависимых сущностей.
Характеристическая – зависимая дочерняя сущность, которая связана только с одной родительской и по смыслу хранит информацию о характеристиках родительской сущности.
Ассоциативная – сущность, связанная с несколькими родительскими сущностями. Такая сущность содержит информацию о связях сущностей.
Именующая – частный случай ассоциативной сущности, не имеющей собственных атрибутов (только атрибуты родительских сущностей, мигрировавших в качестве внешнего ключа).
Категориальная – дочерняя сущность в иерархии наследования.
Иерархия наследования (subtype relationship), или иерархия категорий, представляет собой особый тип объединения сущностей, которые разделяют общие характеристики. Например, в организации работают служащие, занятые полный рабочий день (штатные служащие), и совместители. Из их общих свойств можно сформировать обобщенную сущность (родовой предок) "Сотрудник" (см. рис. 6.11), чтобы представить информацию, общую для всех типов служащих. Специфическая для каждого типа информация может быть расположена в категориальных сущностях (потомках) "Штатный сотрудник" и "Совместитель".
Обычно иерархию наследования создают, когда несколько сущностей имеют общие по смыслу атрибуты либо когда сущности имеют общие по смыслу связи (например, если бы "Штатный сотрудник" и "Совместитель" имели сходную по смыслу связь "работает в" с сущностью "Организация"), либо когда это диктуется бизнес-правилами.
Для каждой категории можно указать дискриминатор (discriminator) – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой (атрибут Тип на рис. 6.11).

Рис. 6.11. Иерархия наследования. Неполная категория
Иерархии категорий делятся на 2 типа – полные и неполные. В полной иерархии категорий (Complete subtype relationship) одному экземпляру родового предка (сущность "Сотрудник", рис. 6.12) обязательно соответствует экземпляр в каком-либо потомке, т. е. в этом примере служащий обязательно является либо совместителем, либо консультантом, либо постоянным сотрудником.
Если категория еще не выстроена полностью и в родовом предке могут существовать экземпляры, которые не имеют соответствующих экземпляров в потомках, то такая категория будет неполной (Incomplete subtype relationship). На рис. 6.11 показана неполная категория – сотрудник может быть не только постоянным или совместителем, но и консультантом, однако сущность "Консультант" еще не внесена в иерархию наследования.
На рис. 6.12 показан пример полной категории.

увеличить изображение
Рис. 6.12. Иерархия наследования. Полная категория
Полная категория помечается символом  , неполная –
, неполная –  .
.
Возможна комбинация полной и неполной категорий. Помимо постоянных сотрудников и совместителей могут быть и консультанты, которые могут быть не отражены в иерархии (неполная категория), но каждый постоянный сотрудник либо мужчина, либо женщина (полная категория).
Рассмотрим возможные стадии построения иерархии наследования.
1. Определение сущностей с общими (по определению) атрибутами.
Предположим, в процессе проектирования созданы сущности "Штатный сотрудник" и "Совместитель" ( рис. 6.13). Можно заметить, что часть атрибутов у этих сущностей ( Фамилия, Имя, Отчество, Дата рождения, Должность ) имеет одинаковый смысл.

Рис. 6.13. Сущности с общими по смыслу атрибутами
2. Перенос общих атрибутов в сущность – родовой предок. В случае обнаружения совпадающих по смыслу атрибутов следует создать новую сущность "Сотрудник" – родовой предок, и перенести в нее общие атрибуты ( Фамилия, Имя, Отчество, Дата рождения, Должность ).
3. Создание неполной структуры категорий. Создается категориальная связь от новой сущности – родового предка к старым сущностям-потомкам. Новая сущность дополняется атрибутом – дискриминатором категории ( Тип ) (см. рис. 6.11).
4. Создание полной структуры категорий. Проводится дополнительный поиск сущностей, имеющих общие по смыслу атрибуты с родовым предком. В примере это сущность "Консультант" ( рис. 6.14).

Рис. 6.14. Дополнительная сущность с общими по смыслу атрибутами
Общие атрибуты переносятся в родового предка, и категория преобразуется в полную. Сущность "Консультант" не имеет атрибута Должность, поэтому в родовом предке значение этого атрибута в случае консультанта будет NULL. В зависимости от бизнес-правил атрибут Должность может быть перенесен обратно из родового предка в сущности-потомки "Штатный сотрудник" и "Совместитель".
5. Комбинации полной и неполной структур категорий. При необходимости создание иерархии категорий можно продолжить. Для каждого потомка может найтись сущность с общими атрибутами, тогда сущность-потомок становится родовым предком для новых потомков и т. д.
Нормализация модели "сущность-связь"
Имеются 3 подуровня логического уровня модели данных, отличающихся по глубине представления информации о данных:
· диаграмма "сущность-связь" (Entity Relationship Diagram, ERD);
· модель данных, основанная на ключах (Key Based model, KB);
· полная атрибутивная модель (Fully Attributed model, FA).
Диаграмма "сущность-связь" (ER-диаграмма) отображает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к ИС. Диаграмма "сущность-связь" может отображать связи "многие ко многим" и не включать описание ключей. Как правило, ER-диаграммыиспользуются для презентаций и обсуждения структуры данных с экспертами предметной области.
Модель данных, основанная на ключах, – более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области.
Полная атрибутивная модель – наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи.
Рассмотрим теперь процесс нормализации данных, который сопровождает создание полной атрибутивной модели.
Нормализация – процесс проверки и реорганизации сущностей и атрибутов с целью удовлетворения требований к реляционной модели данных. Нормализация позволяет быть уверенным, что каждый атрибут определен для своей сущности, значительно сократить объем памяти для хранения информации и устранить аномалии в организации хранения данных. В результате проведения нормализации должна быть создана структура данных, при которой информация о каждом факте хранится только в одном месте.
Процесс нормализации сводится к последовательному приведению структуры данных к нормальным формам – формализованным требованиям к организации данных. Известно 6 нормальных форм:
· первая нормальная форма (1NF) ;
· вторая нормальная форма (2NF) ;
· третья нормальная форма (3NF) ;
· нормальная форма Бойса-Кодда (усиленная 3NF);
· четвертая нормальная форма (4NF) ;
· пятая нормальная форма (5NF).
На практике обычно ограничиваются приведением данных к третьей нормальной форме. В данном подразделе будут достаточно кратко рассмотрены первые три нормальные формы и, в качестве иллюстрации, четвертая нормальная форма. Для углубленного изучения нормализации следует рекомендовать книгу [Дейт].
Нормальные формы основаны на понятии функциональной зависимости (в дальнейшем будет использоваться термин "зависимость"). Приведем формальное определение для функциональной зависимости.
Функциональная зависимость (FD). Атрибут B сущности E функционально зависит от атрибута A сущности E тогда и только тогда, когда каждое значение A в E связало с ним точно одно значение B в E, т. е. A однозначно определяет B.
Полная функциональная зависимость. Атрибут B сущности E полностью функционально зависит от ряда атрибутов A сущности E тогда и только тогда, когда B функционально зависит от A и не зависит ни от какого подмножества атрибутов A.

Рис. 6.15. Ненормализованная сущность "Сотрудник"
На рис. 6.15 в сущности "Сотрудник" значения атрибутов Фамилия, Имя и Отчество однозначно определяются значением атрибута Табельный номер, т. е. атрибуты Фамилия, Имя и Отчество зависят от атрибута Табельный номер.
Функциональные зависимости определяются бизнес-правилами предметной области. Так, если оклад сотрудника определяется только должностью, то атрибут Оклад зависит от атрибута Должность ; если оклад зависит еще, например, от стажа, то такой зависимости нет. В нижеследующих примерах будем считать для определенности, что такая зависимость есть.
Рассмотрим нормальные формы.
Первая нормальная форма (1NF) Сущность находится в первой нормальной форме тогда и только тогда, когда все атрибуты содержат атомарные значения.
Среди атрибутов не должно встречаться повторяющихся групп, т. е. несколько значений для каждого экземпляра. На рис. 6.15 атрибуты Телефон и Хобби могут представлять повторяющиеся группы и тем самым нарушать требования первой нормальной формы. Сотрудник может иметь несколько рабочих телефонов или иметь несколько увлечений (рыбалка, охота, плавание). Добавление в сущность нескольких атрибутов для представления значений повторяющейся группы не является решением проблемы, поскольку в большинстве случаев нельзя заранее точно определить, сколько таких значений может быть.
Нарушением требований нормализации является хранение в одном атрибуте разных по смыслу значений. На рис. 6.15 атрибут Дата зачисления или увольнения хранит информацию как о зачислении, так и об увольнении сотрудника. Если хранится только одно значение, то невозможно понять, какая именно дата внесена. Если внести атрибут-признак типа даты, тип можно будет определить, но останется возможность хранения только одной даты для каждого сотрудника.
Для приведения сущности к первой нормальной форме следует:
· разделить сложные атрибуты на атомарные;
· создать новую сущность;
· перенести в нее все "повторяющиеся" атрибуты;
· выбрать возможный ключ для нового PK (или создать новый PK);
· установить идентифицирующую связь от прежней сущности к новой, PK прежней сущности станет внешним ключом (FK) для новой сущности.
На рис. 6.16 показана сущность "Сотрудник", приведенная к первой нормальной форме.

Рис. 6.16. Сущность "Сотрудник", приведенная к первой нормальной форме
Вторая нормальная форма (2NF) Сущность находится во второй нормальной форме, если она находится в первой нормальной форме и каждый неключевой атрибут полностью зависит от первичного ключа (не должно быть зависимости от части ключа). Вторая нормальная форма имеет смысл только для сущностей, имеющих сложный первичный ключ.

Рис. 6.17. Сущность "Проект"
Предположим, что сущность "Проект" содержит информацию о проекте, которым руководит сотрудник, причем информация содержится как непосредственно о проекте, так и о руководителе проекта ( рис. 6.17). Атрибуты Фамилия, Имя, Отчество и Должность зависят только от атрибута табельный номер руководителя, но вовсе не от атрибута Наименование проекта. Другими словами, имеется зависимость только от части ключа.
Для приведения сущности ко второй нормальной форме следует:
· выделить атрибуты, которые зависят только от части первичного ключа, создать новую сущность;
· поместить атрибуты, зависящие от части ключа, в их собственную (новую) сущность;
· установить идентифицирующую связь от прежней сущности к новой ( рис. 6.18).

Рис. 6.18. Сущность "Проект", приведенная ко второй нормальной форме
Вторая нормальная форма позволяет избежать следующих аномалий при выполнении операций:
· обновления (UPDATE). Происходит дублирование данных о сотруднике, если он руководит несколькими проектами. Если данные о сотруднике изменяются, необходимо менять несколько записей (по числу ведомых проектов);
· вставки (INSERT). Невозможно ввести данные о сотруднике, если он в данный момент не руководит проектами;
· удаления (DELETE). Если сотрудник временно прекращает руководство проектами, данные о нем теряются.
На рис. 6.18 показана сущность "Проект", приведенная ко второй нормальной форме.
Третья нормальная форма (3NF). Сущность находится в третьей нормальной форме, если она находится во второй нормальной форме и никакой неключевой атрибут не зависит от другого неключевого атрибута (не должно быть взаимозависимости между неключевыми атрибутами).
На рис. 6.16 сущность "Сотрудник" находится во второй нормальной форме (имеется только один атрибут первичного ключа, поэтому не может быть зависимости неключевых атрибутов от части ключа), но неключевой атрибут Оклад зависит от другого неключевого атрибута – Должности.
Для приведения сущности к третьей нормальной форме следует:
· создать новую сущность и перенести в нее атрибуты с одной и той же зависимостью от неключевого атрибута;
· использовать атрибут (атрибуты), определяющий (определяющие) эту зависимость, в качестве первичного ключа новой сущности;
· установить неидентифицирующую связь от новой сущности к старой ( рис. 6.19).

увеличить изображение
Рис. 6.19. Сущность "Сотрудник", приведенная к третьей нормальной форме
В третьей нормальной форме каждый атрибут сущности зависит от ключа, от всего ключа целиком и ни от чего другого, кроме как от ключа.
Третья нормальная форма также позволяет избежать ряда аномалий.
· Обновление (UPDATE). Происходит дублирование данных об окладе, если должность занимают несколько сотрудников. Если оклад, соответствующий должности, меняется, необходимо менять несколько записей (по числу сотрудников на одной должности).
· Вставка (INSERT). Невозможно ввести данные об окладе, соответствующем должности, если в данный момент нет сотрудника, занимающего эту должность.
· Удаление (DELETE). В случае удаления из таблицы сотрудника, занимающего уникальную должность, данные об окладе теряются.
Четвертая нормальная форма (4NF) требует отсутствия многозначных зависимостей между атрибутами.
В примере на рис. 6.20 (слева) преподаватель читает лекции по нескольким предметам и курирует несколько групп студентов. Одна группа студентов может изучать несколько предметов, одному предмету могут обучаться несколько групп студентов. Имеется многозначная зависимость между атрибутами Предмет и Группа. При этом возможна аномалия: если у преподавателя появляется новая группа, приходится добавлять несколько записей, по числу читаемых предметов.
Для приведения сущности к четвертой нормальной форме следует создать новую сущность и перенести атрибуты с многозначной зависимостью в разные сущности ( рис. 6.20, справа). Связь между новыми сущностями при этом устанавливать нельзя, поскольку в результате миграции атрибутов внешних ключей атрибуты с многозначной зависимостью вновь окажутся в одной сущности. Ссылочную целостность в этом случае следует поддерживать при помощи триггеров.

Рис. 6.20. Иллюстрация четвертой нормальной формы
Резюме
Метод моделирования "сущность-связь" был предложен С. Ченом в 1976 году. Ряд исследователей разработали несколько графических нотаций для представления элементов модели. Проектировщик ХД может выбрать графическую нотацию по своему вкусу.
Применение метода моделирования "сущность-связь" помогает проектировщикам создать логическую модель предметной области, не зависимую от программно-аппаратной реализации. Этот метод используется как при моделировании предметных областей OLTP-систем, так и при моделировании предметных областей BI-систем. Знание этого метода помогает проектировщику ХД быстрее установить логические связи между моделями БД OLTP-систем масштаба организации и моделями ХД BI-систем.
Независимо от выбранной нотации, действия проектировщика ХД при ER-моделировании сводятся к следующему алгоритму.
Для каждой сущности предметной области базы данных необходимо:
· получить список атрибутов сущности ;
· определить функциональные зависимости;
· определить возможные ключи, в частности, рассмотрев уникальный идентификатор сущности ;
· выполнить нормализацию сущности;
· назначить первичные ключи новых, полученных в результате нормализации сущностей;
· сформировать бизнес-правила поддержки целостности сущности.
Для каждой связи между сущностями необходимо:
· определить мощность связи;
· определить обязательность вхождения сущности в связь;
· разрешить связи "многие ко многим";
· назначить первичные ключи ассоциативных сущностей, исходя из уникального идентификатора связи и процедуры миграции ключей при нормализации;
· определить неключевые атрибуты ассоциативных сущностей, если они необходимы;
· сформировать бизнес-правила поддержки целостности связей;
· документировать логическую модель реляционной базы данных;
· проверить логическую модель реляционной базы данных;
Схема данных
Данная статья является анонсом новой функциональности.
Не рекомендуется использовать содержание данной статьи для освоения новой функциональности.
Полное описание новой функциональности будет приведено в документации к соответствующей версии.
Полный список изменений в новой версии приводится в файле Updates_ru.htm.
Реализовано в версии 1.5.0.1122.
В среде разработки 1C:Enterprise Development Tools (EDT) мы реализовали новый, можно сказать, экспериментальный инструмент. Он, как и дерево объектов конфигурации, предназначен для того, чтобы представить разработчику всё прикладное решение.
Однако для этого он использует другую модель визуализации, в которой структуры данных представляются в виде так называемой ER-диаграммы (Entity Relationship Diagram). Новый инструмент мы назвали схема данных, поскольку ER-диаграмма представляет собой множество прямоугольников, связанных линиями.

Прежде чем рассказать о новом инструменте, нужно сделать небольшое отступление о ER-модели данных вообще. До сих пор эта модель не использовалась 1С:Предприятием, поэтому у вас может возникнуть естественный вопрос, зачем она понадобилась сейчас, и можно ли обойтись без неё.
Зачем в 1С:Предприятии понадобилась ER-модель
Необходимость использования этой модели данных в 1С:Предприятии прямо связана с ростом платформы и значительным усложнением прикладных решений. По этой же причине мы реализовали схему данных в составе новой среды разработки EDT, которая ориентирована именно на большие конфигурации.
Если посмотреть на любую базу данных 1С:Предприятия то вы увидите, что она основана на реляционной модели. Грубо говоря, она состоит из таблиц, которые связаны между собой различными способами. Таблицы имеют поля, из этих полей формируются ключи, которые позволяют связывать таблицы друг с другом.
Такая модель удобна для компьютерной обработки, но неудобна для визуального представления разработчику. Особенно неудобна она в случае 1С:Предприятия, где большинство таблиц имеет не абстрактное, а совершенно конкретное прикладное значение.
Поэтому исторически в конфигураторе 1С:Предприятия используется другая концептуальная модель, представляющая базу данных в виде дерева объектов конфигурации. Объекты конфигурации скрывают за собой реляционную модель, они сгруппированы по принадлежности к тому или иному классу прикладных задач. Такое представление удобно для быстрого нахождения нужных объектов, изменения их свойств и т.д. Однако это представление не даёт простого и наглядного понятия о взаимной связи разных объектов между собой.

Современные прикладные решения 1С:Предприятия содержат большое количество объектов конфигурации, 10 тысяч и более. При таком количестве объектов задача нахождения их взаимных связей с помощью имеющихся инструментов становится довольно трудоёмкой. Причём трудоёмкость растёт не только за счёт прямого увеличения времени поиска ссылок среди большого количества объектов. Она растёт и косвенно, за счёт того, что найденные связи необходимо как-то запомнить и визуализировать. И если таких связей много, встаёт вопрос выбора подходящего внешнего инструмента.
Использование ER-модели (Entity-Relationship Model) как раз решает эту проблему. ER-модель представляет любую структуру данных в виде совокупности сущностей, обладающих атрибутами. Эти сущности взаимодействуют между собой при помощи связей.
В наших терминах, в терминах 1С:Предприятия, сущность это объект конфигурации, а атрибут это реквизит объекта конфигурации в широком смысле: реквизит, измерение, ресурс и т.д. Таким образом, ER-модель базы данных 1С:Предприятия это набор (никак не структурированный) объектов конфигурации (с их реквизитами), между которыми существуют некоторые связи. А схема данных это инструмент, позволяющий визуализировать эту модель.
Всё это теоретическое отступление мы написали только ради того, чтобы обратить ваше внимание на две важные вещи.
Во-первых, схема данных это не что-то опциональное, это не «бантик», добавляющий привлекательности среде разработки. Это вполне себе самостоятельный инструмент моделирования предметной области, обладающий своими преимуществами и особенностями.
Во-вторых, схема данных это не аналог и не замена дерева объектов конфигурации. Это ещё один инструмент разработки, но он, можно сказать, имеет свою собственную аудиторию.
Дерево объектов конфигурации в большей степени удобно для разработчиков, глубоко погруженных в прикладное решение, или знакомых с его генезисом. Оно позволяет быстро модифицировать приложение, при этом большую часть информации о взаимной связи объектов разработчик прекрасно знает, и обычно просто держит в голове.
В отличие от дерева объектов схема данных ориентирована скорее на тех разработчиков, которые не знакомы с прикладным решением глубоко, но которым необходимо быстро разобраться в устройстве какой-то его части. Также схема данных удобна для документирования разрабатываемых механизмов (в том числе и самими разработчиками), поскольку в понятном виде показывает связи между объектами или группами объектов.
Дальше, без общих рассуждений, мы просто хотим показать вам несколько практических сценариев использования схемы данных. Они помогут вам не только понять её назначение, но и узнать её возможности.
Сценарий 1. Какие объекты конфигурации использует данный объект
Это самый простой сценарий. Например, у вас есть регистр Продажи. Вам нужно узнать, какие объекты конфигурации использует это регистр. То есть, на какие объекты конфигурации ссылаются его реквизиты, измерения и ресурсы.
Раньше для этого вы раскрыли бы его структуру в дереве объектов конфигурации и вручную смотрели бы типы реквизитов в палитре свойств. Если регистр большой, то, возможно, вы использовали бы команду Поиск ссылок в объекте. После этого каким-то образом вам нужно было записать то, что вы нашли.
Теперь эта задача решается значительно проще. Вы открываете редактор объекта конфигурации и переходите на закладку Схема данных. Такая закладка есть у всех прикладных объектов конфигурации.

EDT сразу же показывает вам ER-диаграмму. В неё включаются все объекты первого уровня, которые использует регистр Продажи.
На этой схеме данных видно, что регистр Продажи использует документ РасходТовара и справочники Товары и Контрагенты. Эти связи исходят из регистра. Кроме этого на схеме показаны и взаимные связи между самими используемыми объектами (между документом и справочниками).
Вообще говоря, связей может быть много. Чтобы легче ориентироваться в них вы можете выделить мышью исследуемый объект, и тогда исходящие из него связи будут подсвечены. Также будут подсвечены и реквизиты объекта, задействованные в этих связях.

Если вас интересует только одна связь, вы можете нажать на неё, и тогда будет подсвечена она и реквизит, связанный с ней.
Обычно связи обозначаются открытой стрелкой, но для некоторых связей мы используем специальные обозначения: закрытая стрелка и ромб. Например, другая схема данных может выглядеть так:

Закрытой стрелкой обозначается связь с владельцем, а ромбом – с регистратором. Это помогает визуально отличать «техногенные» связи от прикладных.
Такую схему данных, которая открывается на закладке редактора объекта конфигурации, вы можете изменять и модифицировать: раскрывать группы реквизитов, перетаскивать объекты, располагая их более удобным образом, и т.д.
Но нужно учитывать, что эти изменения не сохраняются в конфигурации. Ту схему, которую вы видите, вы можете сохранить как картинку или напечатать (всю схему, или только её часть). Но в следующий раз, когда вы откроете редактор объекта конфигурации и перейдёте на закладку Схема данных, схема будет нарисована заново в стандартном виде.
Поэтому здесь, в этом месте, не нужно увлекаться наведением «красоты», для этого есть другой сценарий, который мы тоже рассмотрим далее.
Сценарий 2. Разобраться с устройством механизма или подсистемы
Второй сценарий заключается в том, что вам нужно разобраться с устройством незнакомого механизма или подсистемы. Например, нужно понять, как устроена подсистема ТоварныеЗапасы. Какие объекты в ней задействованы и как они связаны друг с другом.

В этом случае, как и в первом сценарии, вы можете открыть редактор этой подсистемы и перейти на закладку Схема данных. Здесь вы увидите более интересную картину, потому что кроме объектов на этой схеме будут показаны и подчинённые подсистемы.
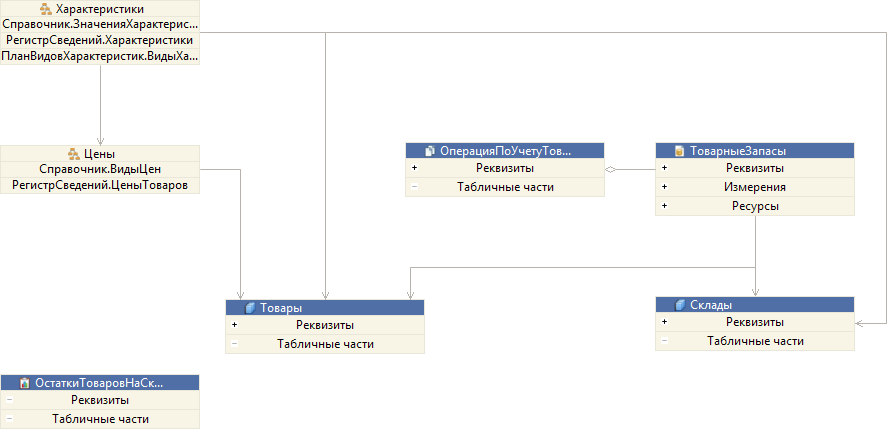
Подсистемы являются группами объектов. Содержащиеся в них объекты имеют связи с объектами, которые находятся «снаружи». Чтобы посмотреть, как устроена любая из этих подсистем, например подсистема Характеристики, вы можете кликнуть на ней прямо в схеме, и увидите её устройство.

Интересным моментом является то, что схема данных поддерживает переходы Вперед / Назад по аналогии с браузерами. Поэтому, разобравшись с устройством этой подчинённой подсистемы, вы можете просто нажать кнопку Назад, и вернуться к предыдущей схеме.
Сценарий 3. Документирование
Третий сценарий заключается в том, что вам нужно документировать некоторый механизм конфигурации. Например, по мере того, как вы его разрабатываете. Или наоборот, когда он уже разработан кем-то другим и полностью готов.
Отличие этого сценария от предыдущих заключается в том, что работа со схемой данных выполняется в течение длительного времени. А это значит, что схема должна быть сохранена в том виде, в котором вы её оставили. Чтобы в следующий раз вы могли продолжить работу с ней с этого же места.
Для такой задачи вам не нужно использовать закладку Схема данных, которая есть у редакторов объектов конфигурации. Нужно создать отдельный файл схемы данных, который вы сможете затем сохранить в своём проекте. Сделать это можно с помощью меню Файл – Создать– Прочие…

Например, вы разрабатываете механизм работы с пользователями, и для его документирования хотите использовать схему данных. Тогда вы самостоятельно формируете схему, перетаскивая в неё из навигатора 1С:Предприятие нужные вам объекты. Например, справочник Пользователи.

После этого вы можете, например, воспользоваться контекстным меню, и добавить в схему все объекты, которые используют справочник Пользователи.

Схема примет у вас такой вид:

Здесь видно, что справочник Пользователи используется в документе Заказ и в плане обмена Мобильные. Чтобы лучше видеть, в каких именно реквизитах он задействован, вы можете раскрыть группы реквизитов и раздвинуть блоки объектов по ширине.

После этого, скорее всего, схема примет не очень красивый вид.

Чтобы сделать её «читабельной» вы можете не перетаскивать объекты мышью, а использовать команду Автоматическое расположение. Она заново расположит объекты в схеме, не меняя их размеров.

Если вам нужны другие объекты, зависящие от показанных, вы снова можете воспользоваться контекстным меню. Добавьте, например, справочник Склады, на который ссылается реквизит документа Склад:

В схеме появится справочник Склад.

Как мы уже говорили в начале примера, схему данных, составленную таким образом, вы можете сохранить в своём проекте. По мере разработки легко поддерживать её актуальность. Если объекты, участвующие в схеме, были модифицированы, вы просто открываете схему и нажимаете кнопку Обновить, которая есть в командной панели. Схема будет перерисована в соответствии с актуальным состоянием конфигурации.
Для редактирования схемы данных есть довольно широкие возможности. Вы можете двигать линии связей.

Передвигая объекты, вы можете выравнивать их относительно соседних объектов при помощи направляющих. Направляющие отображаются автоматически.

Линии связей можно изгибать, добавляя в них точки изгиба, или наоборот, выпрямлять, удаляя эти точки.

Если вы «перемудрили» со связями, или не получается хорошо расставить их вручную, вы можете воспользоваться командой Автоматическое построение связей.

Эта команда, не изменяя размеры и положение объектов, построит связи заново.

Бывают ситуации, когда часть объектов, представленных в схеме данных, объединена некоторой собственной общей задачей, и подробности их внутреннего взаимодействия между собой не важны. Например, вы вывели в схему объекты, которые используют справочник Регионы.

Кроме справочника Контрагенты его используют также план видов характеристик и регистр сведений. Но эти объекты не являются какими-то самостоятельными сущностями, взаимодействие которых между собой интересно в этой схеме. Они являются частью механизма характеристик, реализованного в прикладном решении. Поэтому вы можете выделить их мышью и объединить в группу.

В результате схема примет более простой вид, из которого будет понятно, что справочник Регионы используется только справочником Контрагенты. Но кроме этого, как и подавляющее большинство объектов этого прикладного решения, он задействован в механизме характеристик. Подробности этого механизма в данном случае не важны.

Обратите внимание, что для группы вы можете задать собственное название, которое хорошо отражает её смысл.
Ещё одна оформительская возможность, которая будет полезна, это комментарии. С их помощью вы можете делать поясняющие надписи или оставлять для себя заметки по дальнейшей модификации схемы данных. Комментарии добавляются и редактируются с помощью контекстного меню.

Схемы данных, построенные EDT или созданные вами, могут быть довольно большими. Для навигации по ним приходится прокручивать экран по вертикали и горизонтали. Чтобы не «заблудиться» в больших схемах вы можете использовать окно навигатора, которое открывается командой из панели инструментов.

Оно показывает ту часть схемы, которая в данный момент отображается на экране. Передвигаться по схеме вы можете не только прокручивая экран, но и перемещая мышью область выделения в окне навигатора.
Помимо всего перечисленного в настройках проекта вы можете выбрать одну из предопределенных тем для оформления схем данных, или задать собственные цветовые настройки.

Сценарий 4. Разработка
Как вы видите из третьего примера, схема данных может быть довольно удобным инструментом для документирования некоторого механизма. Но пользоваться ей можно не только после того, как механизм разработан, но и в процессе его разработки.
Прямо сейчас мы реализовали только одну функцию – это переход из схемы данных в редактор объекта конфигурации.

Но теоретически ничто не мешает реализовать и другие функции разработки. Например, создание новых реквизитов объекта не путём их добавления в дерево объектов конфигурации, а путём «протягивания» связи от одного объекта к другому в схеме данных.
Как мы говорили в начале, схема данных это не только новый, но и в некоторой степени экспериментальный инструмент. Мы, конечно, имеем собственные планы по его дальнейшему развитию, но вместе с этим нас интересуют и ваши мысли по этому поводу. Также нам было бы интересно узнать ваше мнение в том случае, если раньше вам уже приходилось (применительно к 1С:Предприятию) решать подобные задачи сторонними средствами.
Ну и конечно, после выпуска этого функционала мы с интересом познакомимся с примерами его реального использования и будем готовы рассматривать и обсуждать ваши пожелания и замечания к этому механизму.
Дата добавления: 2019-02-22; просмотров: 2126; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!